Abstract
- Time-Series Pre-Trained Models, TS-PTMs에 대한 분석 및 리뷰 제공
1. Introduction
- Time Series Mining(TSM)은 금융, 음성인식, 동작인식 등 다양한 응용분야에서 활용되고 있음
- TSM의 근본적 문제는 시계열 데이터를 어떻게 효과적으로 표현할 것인가에 대한 문제임
- shapelets 과 같은 표현방식의 경우 데이터에서 중요한 패턴만 추출하여 활용하므로 전문가의 도메인 지식에 크게 의존함
- 최근 딥러닝 모델은 머신러닝과 달리 Feature extraction이 없이 자동으로 시계열 표현을 학습하며 TSM에서 큰 성공을 거둠. 그러나 이러한 모델은 대량의 라벨링 데이터를 필요로 함. 그러나 대규모 라벨링 시계열 데이터 구축은 어려움
- 데이터 부족 문제를 해결하기 위해 data augmentation, semi-supervised learning, transfer learning과 같은 기법이 활용되고 있음
- time-series data augmentation의 경우 temporal dependencies, multi-scale dependencies를 고려해야 하므로 더 복잡하며 여전히 전문가의 도메인 지식이 필요함
- semi-supervised learning의 경우 unlabeled data를 사용하나, 의료분야와 같은 특정 경우에서는 unlabeled time series data sample 수집이 어려움
- Transfer learning은 대규모 라벨링 데이터 부족 문제를 해결하는 효과적인 방법 중 하나로 target domain과 연관성이 있고, 대규모로 존재하는 source domain으로 모델을 pre-training 후 소량의 target domain data를 이용해 fine-tuning하는 방식으로 진행됨.
- 최근 Transfer learning을 활용한 Pre-Trained Models(PTMs), 특히 Transformer 기반 PTMs은 CV 및 NLP에서 놀라운 성과를 보이고 있으며 이러한 성과에 영향을 받아 time-series 분야에서도 TS-PTMs를 설계하는 방향으로 나아가고 있음
- PTMs의 장점
- 미리 학습된 가중치를 사용하여 학습 속도를 향상시키고 일반화 성능 향상하는 better initialization
- 도메인 전문가의 개입 없는 Automatic Feature Learning
- Fine tuning을 통한 Effective with small data
TS-PTMs

- 시계열 모델을 pre-training 후 fine-tuning 진행
- source domain으로 Pre-training
- 지도 학습
- 보통 classification, forecasting 작업을 이용해 학습하나, 대규모 라벨링 시계열 데이터가 부족하여 한계 존재
- 비지도 학습
- unlabeled data를 이용하며, 주로 Reconstruction 기반 기법을 활용함
- 자기지도 학습
- 최근 contrastive learning 기법이 각광
- consistency-based learning 및 pseudo labeling 기법을 활용해 학습하는 방법 탐구중
- 지도 학습
- Pre-trained models을 target domain으로 fine-tuning
- classification, anomaly detection 등 downstream task 작업에서 성능 향상
- source domain으로 Pre-training
2 .Background
time-series mining task
- 시계열 데이터의 표현
- $X=[x_1, x_2, ..., x_T]$
- 시계열 데이터를 활용한 주요 task
- time-series classification(TSC)
- $D = \{(X_1, y_1)(X_2, y_2),...(X_N, y_N)\}$
- 의료, 동작 인식 등
- Time-Series Forecasting(TSF)
- input: $X=[x_1, x_2, ..., x_T]$
- output(미래 예측값): $[x_{T+1}, x_{T+2}, ..., x_{T+H}]$
- 주식 가격 예측, 날씨, 교통량 예측 등
- Time-Series Clustering
- temporal Dependency를 고려해야 함
- 다양한 스케일에서의 패턴 분석 필요
- 고객 세분화, 이상 탐지
- Time-Series Anomaly Detection
- 특정 시점 x_t 또는 시퀸스 $S = [x_p, ... x_{p+n-1}]$가 이상치인지 판단
- 금융 사기 탐지, 네트워크 보안
- Time-Series Imputation, TSI
- 누락된 값을 채우는 작업. M은 누락 여부를 나타내는 바이너리 행렬임(1이 관측됨)
- $X_{imputed} = X \cdot M + \hat{X} \cdot (1-M)$
- Time-Series Extrinsic Regression, TSER
- 시계열 데이터를 입력으로 받아 연속적 스칼라 값을 예측
- TSF는 미래의 시계열 값을 예측하는 반면, TSER은 시간과 무관한 외부 값을 예측한다는 점에서 차이가 있음
- time-series classification(TSC)
Deep Learning Models for Time Series
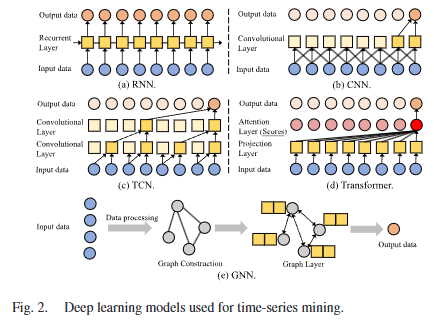
1) 순환 신경망 (Recurrent Neural Networks, RNNs)
- 구조: 입력층, 다중 순환(hidden) 층, 출력층으로 구성
- 특징: 시계열 데이터를 처리하기 적합하지만 장기 의존성(Long-Term Dependency) 문제가 발생
- 주요 모델:
- LSTM (Long Short-Term Memory) [54]: 게이트 구조를 이용하여 장기 의존성 문제 해결
- GRU (Gated Recurrent Unit) [53]: LSTM보다 간결한 구조
2) 합성곱 신경망 (Convolutional Neural Networks, CNNs)
- 특징: 시계열 데이터를 이미지 형태로 변환하여 분석 가능
- 주요 모델:
- TCN (Temporal Convolutional Networks) [61]: 시계열 전용 CNN 모델
- 멀티스케일 CNN [59]: 서로 다른 필터 크기를 사용하여 다양한 패턴을 학습
3) Transformer 모델
- 특징: Self-Attention을 활용하여 장기 의존성을 효과적으로 모델링
- 주요 모델:
- Informer [11]: 기존 Transformer의 O(N^2) 연산량 문제를 해결
- Autoformer [64]: 주파수 분석을 통해 예측 성능 개선
4) 그래프 신경망 (Graph Neural Networks, GNNs)
- 특징: 시계열 데이터를 그래프로 변환하여 다변량 시계열 분석 수행
- 주요 모델:
- GCN (Graph Convolutional Networks) [66]: 그래프 구조에서 지역적 패턴 학습
- ST-GNN (Spatio-Temporal GNNs) [67]: 시공간 패턴 학습
3. Overview of TS-PTM

Supervised PTM
- CV의 Transfer learning에서 영감을 받은, 대규모 데이터셋에서 pretraining 후 작은 타겟 데이터에서 fine tuning 진행하는 방식을 시계열 데이터에도 효과적인지 연구하는 작업
<Classification-based PTM>


- 주로 cross entrophy 사용해서 모델 훈련
- 소규모 시계열 데이터셋에서 CNN 등과 같은 모델이 Overfitting 되는 문제 발생
- 이를 해결하기 위해 transfer learning 기반의 classification 등장
- 종류
| 방법 | 설명 | 대표연구 |
| Universal Encoder | - CNN+Attention 기법을 사용하여 다양한 시계열 데이터에서 공통적인 특징을 학습 - 도메인 간 차이 큰 경우 성능 저하 |
Serrà et al. [71] |
| Aligned Encoder | - 출발 데이터와 타겟 데이터의 도메인 간 차이를 줄이기 위해 도메인 적응(Domain Adaptation) 적용 - MMD(Maximum Mean Discrepancy) 또는 Adversarial Learning 활용 |
Wilson et al. [82] |
| Model Reprogramming | - 원래 다른 태스크에서 학습한 모델을 새로운 시계열 데이터에 적응 - voice2series: 음성 데이터로 학습된 모델을 일반 시계열 데이터에 적용 |
Voice2Series [24] |
<Forecasting-based PTM>


- 과거 데이터를 기반으로 미래 값을 예측하는 작업
- 비지도 학습과 유사하게 라벨 없이도 데이터를 pretraining 할 수 있다는 장점이 있음
| 방법 | 설명 | 대표연구 |
| AutoRegression 기반 PTM | - 시계열 값을 입력으로 받아서 미래 값 예측 - RNN, Transformer 등의 딥러닝 모델을 활용 |
Mallick et al. [106], Du et al. [107] |
| Adaptive Encoder (메타학습 기반 PTM) | 메타 학습(Meta-Learning) 기법을 사용하여 새로운 데이터셋에도 빠르게 적응 | Oreshkin et al. [116] (Zero-Shot Forecasting) |
Unsupervised PTM
<Reconstruction-based PTM>
- 입력 데이터를 AutoEncoder를 이용해서 압축하고 다시 복원하는 과정에서 feature 학습
- 대표 연구: timeNet, Denoising AutoEncoder 등
<Transformer Encoder 기반 PTM>
- NLP의 Masked Language Modeling (BERT)방식을 시계열 데이터에 적용
- 대표 연구: Time-Series Transformer(TST)
Self-supervised PTM
<Consistency-based PTM>

- Contrastive Learning based PTM
- T-Loss, TS2Vec 등
<Pseudo-labeling PTM>
- 데이터에 가상의 의사 라벨을 부여하여 학습
4. Experiments


👉 평가 작업:
- 시계열 분류 (Classification) – UCR [163], UEA [164] 데이터셋 활용
- 시계열 예측 (Forecasting) – 9개 공개 데이터셋 활용
- 이상 탐지 (Anomaly Detection) – Yahoo [166], KPI [167], UCR 이상 탐지 데이터셋 [168] 활용
A. 시계열 분류 성능 평가 (Performance of PTMs on Time-Series Classification)
✅ 데이터셋 구성
- UCR 및 UEA 데이터셋: 훈련/테스트 데이터를 5-Fold Cross-Validation 방식으로 분할하여 실험 진행
- 독립적인 4가지 시계열 데이터셋: 기존 연구 [28]의 데이터셋을 활용
✅ 비교 기법
- 기존 전이 학습(Transfer Learning) 기반 TS-PTMs
- 일반적인 분류 모델(Fully Convolutional Network, FCN)
- 최신 TS-PTMs 모델 (TST, TS2Vec, PatchTST, GPT4TS 등)
1) 전이 학습 기반 TS-PTMs의 효과 분석
👉 UCR 데이터셋을 이용한 실험 결과
방법 최소 크기 데이터셋 중간 크기 데이터셋 최대 크기 데이터셋 평균 정확도
| 지도 학습 기반 전이 학습 (SUP CLS) | 우수함 | 최고 성능 | 우수함 | 최고 |
| 비지도 학습 기반 전이 학습 (RNN AutoEncoder) | 보통 | 중간 | 낮음 | 낮음 |
| 비지도 학습 기반 전이 학습 (FCN AutoEncoder) | 중간 | 낮음 | 낮음 | 낮음 |
결론:
- 지도 학습(SUP CLS) 기반의 전이 학습 방법이 가장 뛰어난 성능을 보임
- 비지도 학습 기반 전이 학습 모델은 성능이 낮았음 (특히 RNN 기반 AutoEncoder)
- FCN을 활용한 전이 학습 방법이 더 효과적
👉 독립적인 4개 데이터셋에서의 실험 결과
데이터셋 일반 CNN 분류 모델 지도 학습 기반 전이 학습 비지도 학습 기반 전이 학습
| 신경 신호 분석(Neural Signal Detection) | 보통 | 우수 | 낮음 |
| 기계 장비 상태 감지(Mechanical Device Diagnosis) | 낮음 | 우수 | 낮음 |
| 활동 인식(Activity Recognition) | 중간 | 낮음 | 우수 |
| 신체 상태 모니터링(Physical Status Monitoring) | 낮음 | 낮음 | 낮음 |
결론:
- 전이 학습은 특정 도메인에서 효과적이지만, 데이터셋에 따라 성능 차이가 있음
- 활동 인식 분야에서는 비지도 학습 기반 전이 학습이 더 좋은 성능을 보임
2) 최신 TS-PTMs 모델 비교 분석
👉 UCR 및 UEA 데이터셋에서의 분류 성능 비교
모델 UCR 데이터셋 정확도 UEA 데이터셋 정확도
| TS2Vec | 최고 성능 (Rank #1) | 보통 |
| GPT4TS | 우수함 (Rank #2) | 최고 성능 |
| PatchTST | 중간 | 우수함 |
| FCN (기본 CNN 모델) | 보통 | 우수함 |
| TimesNet | 낮음 | 낮음 |
결론:
- TS2Vec과 GPT4TS가 UCR 데이터셋에서 가장 우수한 성능을 보임
- GPT4TS는 UEA 데이터셋에서 가장 좋은 성능을 기록
- PatchTST는 다변량 시계열 데이터에서 강력한 성능을 보임
- TimesNet은 성능이 낮았음
🚀 Transformer 기반 TS-PTMs (PatchTST, GPT4TS)와 대조 학습(Contrastive Learning) 기반 TS2Vec이 가장 강력한 모델로 확인됨!
B. 시계열 예측 성능 평가 (Performance of PTMs on Time-Series Forecasting)
✅ 비교 기법:
- Transformer 기반 모델 (Informer, Autoformer, iTransformer 등)
- 전통적인 선형 모델 (DLinear)
- 최신 TS-PTMs (GPT4TS, CoST, TS2Vec)
✅ 성능 평가 지표:
- MSE (Mean Squared Error)
- MAE (Mean Absolute Error)
👉 9개 공개 데이터셋에서의 예측 성능 비교
모델 평균 MSE 평균 MAE
| iTransformer | 최고 성능 | 최고 성능 |
| GPT4TS | 우수함 | 우수함 |
| CoST | 우수함 | 중간 |
| Autoformer | 중간 | 우수함 |
| DLinear | 낮음 | 낮음 |
결론:
- iTransformer가 가장 좋은 성능을 보였으며, GPT4TS도 우수한 성능을 기록
- CoST는 일부 데이터셋(Weather, ILI)에서 강력한 성능을 보임
- Autoformer는 중간 수준의 성능을 보였지만, 장기 예측에서는 더 좋은 성능을 기록
🚀 GPT4TS와 iTransformer가 시계열 예측에서 매우 강력한 모델임을 확인!
C. 시계열 이상 탐지 성능 평가 (Performance of PTMs on Time-Series Anomaly Detection)
✅ 비교 기법:
- 기존 모델: LSTM-VAE, DONUT, Spectral Residual(SR)
- 최신 TS-PTMs: TS2Vec, GPT4TS, DCdetector
✅ 평가 지표:
- F1-Score, Precision, Recall
- PA%K (Point Adjustment Score)
- Volume Under the Surface (VUS)
👉 Yahoo 및 KPI 데이터셋에서의 이상 탐지 성능 비교
모델 F1-Score Precision Recall
| TS2Vec | 최고 성능 | 우수함 | 우수함 |
| GPT4TS | 우수함 | 보통 | 최고 |
| Anomaly Transformer (AT) | 중간 | 최고 | 낮음 |
| LSTM-VAE | 낮음 | 낮음 | 낮음 |
결론:
- TS2Vec이 가장 높은 F1-Score를 기록
- GPT4TS는 가장 높은 Recall을 기록하여, 이상 탐지에서 강력한 성능을 보임
- LSTM-VAE 등의 전통적인 모델은 성능이 낮음
🚀 GPT4TS와 TS2Vec이 이상 탐지에서도 뛰어난 성능을 보이며, Transformer 기반 모델이 강력한 효과를 보임!
결론
📌 시계열 분류: TS2Vec, GPT4TS, PatchTST가 최고 성능
📌 시계열 예측: iTransformer, GPT4TS가 최고 성능
📌 이상 탐지: TS2Vec, GPT4TS가 최고 성능
✅ 결론: TS-PTMs 중 Transformer 기반 모델(GPT4TS, PatchTST)과 대조 학습 기반 모델(TS2Vec)이 가장 강력한 성능을 보임! 🚀
5. Future Directions
- 해결 필요한 문제들
- 데이터셋 문제
- 대규모 라벨링된 시계열 데이터의 부족
- UCR, UEA 등의 데이터셋이 있지만 대부분 소규모 데이터셋임
- 도메인 간 차이 문제
- 각 데이터간 데이터 분포가 다름
- 다양한 도메인에 적합한 범용 TS-PTM이 필요
- 대규모 라벨링된 시계열 데이터의 부족
- 심층 학습 모델의 한계
- RMM, CMM의 경우 장기 의존성 학습이 어려우며, Transformer의 경우 O(N^2)의 복잡도로 인해 긴 시계열 데이터를 처리하기 어려움
- Transformer 기반 모델 최적화 필요
- 장기 시계열 데이터의 효율적 처리 위한 추가적 최적화 필요
- 시계열 데이터의 교유 특성 활용
- 시계열 데이터는 temporal dependency, multivariate dependency 등 이미지, 텍스트와 다른 독특한 특성을 가짐
- robustness against adversarial attacks
- 딥러닝 모델은 작은 노이즈를 추가하는 것만으로도 성능이 떨어질 정도로 adversarial attack에 취약함
- Dealing with Noisy Labels in Time-Series Data
- 시계열 데이터의 경우 수동 라벨링을 수행하므로 의료, 제조업 등에서 오류 가능성이 있음
- LLM과의 결합 가능성
- GPT-4와 같은 LLM을 시계열 분석에 적용하는 연구 필요
- 데이터셋 문제
6. Conclusion
핵심 연구 결과
✅ 시계열 분류(Classification): TS2Vec, GPT4TS, PatchTST 모델이 가장 우수한 성능을 보임
✅ 시계열 예측(Forecasting): iTransformer, GPT4TS 모델이 강력한 성능을 보임
✅ 이상 탐지(Anomaly Detection): TS2Vec, GPT4TS 모델이 뛰어난 성능을 기록
향후 연구 방향
🚀 대규모 시계열 데이터셋 구축
🚀 Transformer 기반 TS-PTMs 최적화
🚀 GNN + Transformer 결합 연구
🚀 LLMs을 활용한 시계열 분석 연구
<논문 링크>
https://arxiv.org/pdf/2304.08485

