[paper review] 심장소리 분류를 위한 inverted residuals 기반 경량화 모델
논문 읽는 목적
아이펠 과정에서 심음데이터 S1,S2 detection을 주제로 프로젝트를 진행하게 되면서 소리 데이터와 심음 데이터를 처음으로 접하게 되었다. 소리 데이터도 생소한데 특히 심음 데이터의 경우 이해하는 데 어려움이 있어 과거 연구 논문을 읽고 리뷰하자고 생각하였다. 이 논문의 경우 심음 데이터에 대한 기존 연구를 정리해 두어서 읽어보면 좋겠다고 생각했다. 전체적인 논문 내용보다는 인사이트를 중심으로 정리하려고 한다.
기존 심음 이상 유무 분류 연구들
기존 연구들은 다음과 같은 방식들을 기반으로 수행되었다.
1. 심전도(ECG), 엔벨로프 기반 분석, 통계적 모델을 활용해 심장 소리를 분할
2. 분할된 주기에서의 통계치를 특징으로 사용
머신러닝 모델
- 주로 심장 소리의 S1, S2 주기를 추출하여 추출된 주기들의 통계치들을 특징으로 활용하였다.
| 연구자 | 방법 | Total precision |
| Gomes and Pereira | S1, S2 주기 추출 후 주기별 특징을 이용해 DT, 다층 퍼셉트론에 심장소리 분류를 수행하였으며 다층 퍼셉트론이 DT보다 우수한 성능 | 데이터셋 A: 2.12 데이터셋 B: 1.67 |
| Deng and Bently | S1, S2 검출 후 주기의 개수, S1과 S2 사이 길이와 같은 통계적 특징에 따라 심장 소리 분류하는 순서도를 제안 | 데이터셋 A: 1.46 데이터셋 B: 1.31 |
| Balili et al | 심장 소리 S1, S2로 분할한 뒤 S1, 수축기, S2, 확장기에 대하여 이산형 웨이블릿 변환을 통해 100가지 특징을 구하고 이를 RF로 분류 | 데이터셋 A: 2.92 데이터셋 B: 2.04 |
| zhang et al | 1. 심장 소리 신호를 6차 Daubechies 웨이블릿 변환을 통해 재구성 2. AMDF(Average magnitude difference function)를 통해 S1, S2 주기 추정한 뒤 S1 기준으로 분할된 심장주기를 정렬 3. 서로 다른 주기에서 추출된 스펙토그램의 크기를 쌍선형 보간법으로 동일하게 맞춰주고 Partial least squares regression으로 차원 축소 4. SVM 사용해서 분류 진행 |
데이터셋 A: 2.89 데이터셋 B: 1.75 |
| zhang et al | 1. Band pass filter로 심장 소리 잡음 제거 2. 스펙토그램 추출해 쌍선형 보간법으로 스펙토그램 크기 동일하게 맞춤 3. 텐서분해를 통해 차원 축소 4. SVM 수행 |
데이터셋 A: 2.9 데이터셋 B: 1.68 |
| Chakir | 1. 각 데이터셋 특성에 맞는 심장 소리 분할 알고리즘 제한 2. 분할한 심장소리에서 S1, S2 사이 길이, zero crossing, 각 데이터 길이 및 진폭 최소, 최댓값 등 틍직 추출 3. KNN으로 분류 |
데이터셋 A: 2.96 데이터셋 B: 1.58 |
| Bourohou | 1. 4가지 엔벨로프 방법으로 심장 소리 분할 2. 분할된 심장 소리에서 20개 특징 추출 3. KNN, SVM, 트리 기반 분류기, 나이브 베이즈 분류 등 4가지 모델 제안하였으며 나이브 베이즈 분류기의 성능이 가장 좋음 |
데이터셋 A: 3.06 데이터셋 B: 2.37 |
딥러닝 모델
| 연구자 | 방법 | total precision |
| Vrbancic | 심장 소리를 150ms 길이로 분할한 뒤 1D-CNN과 Fully connected layer를 결합한 모델을 통해 자동으로 심장 주기 탐지하는 방법 제안 | |
| Raza | 1. 데이터를 400Hz로 리샘플링 2. band pass filter를 이용해 잡음 제거 3. Repeat 기법으로 데이터 길이 동일하게 설정. repeat 기법은 짧은 데이터 반복, 긴 데이터는 해당 길이까지만 사용하는 방식임. 4. downsampling을 이용해 차원 축소 5. RNN 사용해 분류 |
accuracy 80.8% |
경량화 관련 연구
| 연구자 | 방법 | 성능 |
| Xiao | 1. 소리 데이터를 2000Hz로 리샘플링 2. band pass filter 통과시켜 잡음 제거 3. 3초 길이로 분할한 1차원의 PCG 데이터를 입력 데이터로 사용 4. 모델 경량화를 위해 mobileNetV2의 inverted residual 구조에서 skip connection이 아닌 clique block 적용하여 양방향으로 feature map을 학습할 수 있도록 함 5. majority voting 방식을 이용해 최종 클래스 분류 |
적은 파라미터를 학습하면서 성능 우수 |
| Shouvo | - 데이터를 정상 소리와 4종류의 비정상 소리로 구성 - 비정상 소리: AS(Aortic stenosis), MR(Mitral reguragitation), MS(Mitral stenosis), MVP(Mitral valve prolapse) - 2000Hz로 리샘플링 후 같은 길이로 맞춤 - 병렬 CNN과 Bi-LSTM 사용 |
0.67M 파라미터와 26M FLOPS를 학습에 사용하여 웨어러블 기기 및 모바일 기기에 적합한 구조를 가짐 |
| Li | 1. 잡음 제거 위해 10Hz 이상 대역대 갖는 high pass filter 통과시킴 2. STFT 적용해 특징 추출 3. 2D-CNN 사용해 학습 - 클래스 불균형 보안 위해 손실함수로 FocalLoss 함수 사용 |
선행연구 대비 파라미터 90% 감소 성능 12% 하락 |
기존 방식은 다음과 같은 단점이 있다.
- 심전도의 경우 전문적 의료장비가 필요해 일반인이 측정할 수 없다
- 엔벨로프 기반 분석의 경우 주변 소음 및 비정상 심장 소리에서 잡음의 영향을 받으며 일반 성인과 심장 소리의 패턴이 다른 영유아 또는 신생아, 심장병 환자에게 적용할 수 없다.
- 통계적 모델은 Fundamental Heart sound(FHS)의 특성이 다양하여 모든 FHS 를 모델링하는 데에 한계가 있다.
따라서 기존 방식인 심장소리를 분할하여 분석하는 방법 외의 방식이 필요하다.
또한 기존 연구의 경우 경량화에 대한 연구가 부족하며 모델들을 헬스케어 디바이스에 사용하기 위한 소형화, 경량화를 고려해야 한다.
제안 방법론
이 논문에서 방법론은 다음과 같은 프레임워크에서 수행된다.
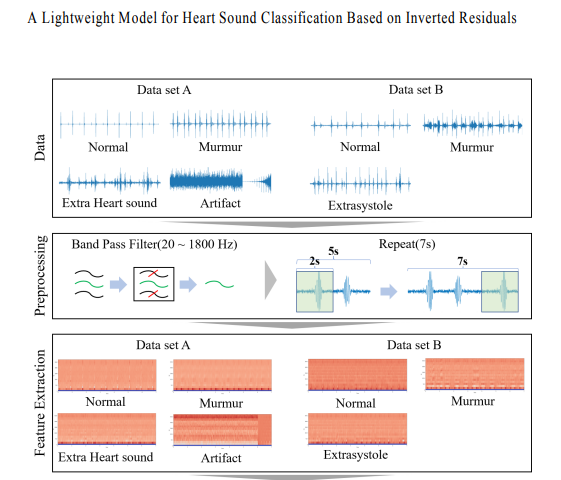
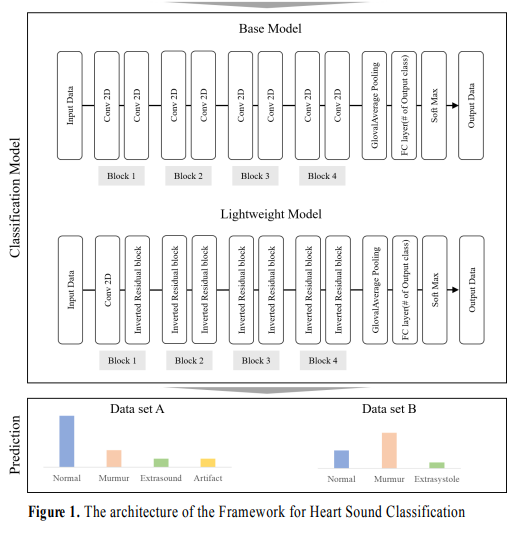
0. 목표: 경량화 모델을 사용해 심장 소리 이상 유무 분류
1. 데이터: PASCAL 데이터를 기반으로 dataset A, B로 구성되며 A는 4개의 클래스를, B는 3개의 클래스를 가짐
2. 전처리: Band pass filter를 통해 잡음 제거, 이후 repeat 기법으로 모든 데이터 길이 동일하게 맞춤
3. 특징 추출: MFCC 사용 - 입력된 신호를 특정 주파수 구간의 에너지 계수 형태로 나타내는 방식
4. 모델: CNN 기반의 Inverted Residual 구조 사용한 경량화 모델
전처리
- 데이터를 4000Hz로 리샘플링
- 20~1800Hz 대역대의 band pass filter 통과시킴
- 데이터 길이 평균인 7초를 기준으로 repeat 기법 적용시킴(Raza et al. 2019)
- repeat 기법은 심장 소리의 주기 검출과 같은 기법을 적용하지 않고도 간단한 전처리로 데이터를 모두 동일한 길이로 변경시킬 수 있다는 장점이 있다.
전처리 수행 전후 비교

특징 추출(MFCC)
데이터 전처리 후 1D 신호를 2D 시간-주파수 신호로 변환시키기 위해 MFCC(Mel-Frequency Cepstral Coeffient)로 특징을 추출한다.
MFCC( MFCC(Mel-Frequency Cepstral Coeffient) )
- 입력된 신호의 단위 에너지를 추출하는 방법
생각한 점
total precision은 0~1사이 값 아닌가?
리샘플링을 하는 이유?
ban pass filter?
repeat 기법?
데이터 특징추출은 필수적인 단계인가?


