[Boostcourse beyond ai] Optimization
Important concepts in optimization
generalization
많은 경우 모델 제작시의 목적
Test error과 training error간의 차이
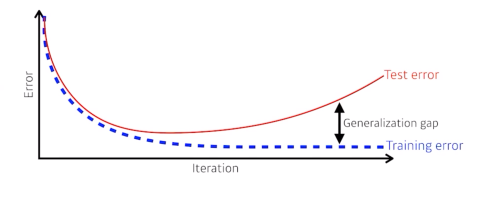
underfitting vs overfitting
overfitting
학습 데이터에 대해서는 잘 작용하지만, 테스트 데이터에 대해서는 잘 작동 x
underfitting
network가 너무 간단하거나 학습데이터가 너무 적음

cross-validation
보통은 traindata와 validation data를 나눠서 학습
train data와 validation data를 얼마나 나누는 것이 좋을까?
데이터 분할시의 데이터 부족을 해결하기 위해 등장한 cross validation
k-fold: 학습 데이터를 k개로 나누고 그 중 1개를 validation으로 나머지를 test로 돌아가면서 k번 학습
딥러닝시 수많은 파라미터가 존재할 때 cross validation을 통해 최적의 hyperparameter 정하고, 이후에 고정된 hyperparameter로 모든 데이터셋 사용

boostrapping
학습 데이터가 100개가 있으면 전부 사용하는게 아니라 80개씩 뽑아서 여러개 모델 생성
하나의 입력에 대해 여러 모델들의 예측값이 얼마나 일치하는지를 보고 전체적 경향 확인
bagging and boosting

bagging
학습 데이터가 10만개로 고정되어있을때 일부만 random sampling하여 모델 여러개 생성하고 평균값
boosting
학습데이터가 100개가 있으면 간단한 모델 1개를 만들고 예측 수행.
2번째 모델은 첫번째 모델에서 잘 예측하지 못했던 20개의 데이터에 대해서만 모델 생성
이런 식으로 여러 모델을 만들어서 합침(하나하나의 weak learner들을 합쳐 strong learner 생성)
bias and variance
low bias, low variance가 좋음
variance: 값이 얼마나 퍼져 있는지
bias: 값이 얼마나 편향되어 있는지

bias and variance tradeoff
내 학습 데이터에 noise가 껴져있다고 가정할때, total noise를 줄이기 위해서는 bias와 variance를 모두 줄이긴 힘듦

'AI Theory' 카테고리의 다른 글
| [시계열 데이터] 1. introduction (0) | 2023.08.29 |
|---|---|
| [23.07.20.] 서울대학교 Data Science Day Review (0) | 2023.07.21 |
| [boostcourse beyond ai] Nueral Network (0) | 2023.05.29 |
| [Paper Review] You Only Look Once: Undefied, Real-Time Object Detection (0) | 2023.02.15 |


