[Paper Review] You Only Look Once: Undefied, Real-Time Object Detection
2016년 당시 object detection에서 처음으로 1-stage detection 방식 제안
object detection이란?
이미지 내 multiful object에 대한 class probability(object classification)와 location 정보(object localization) 추출
object detection의 방식
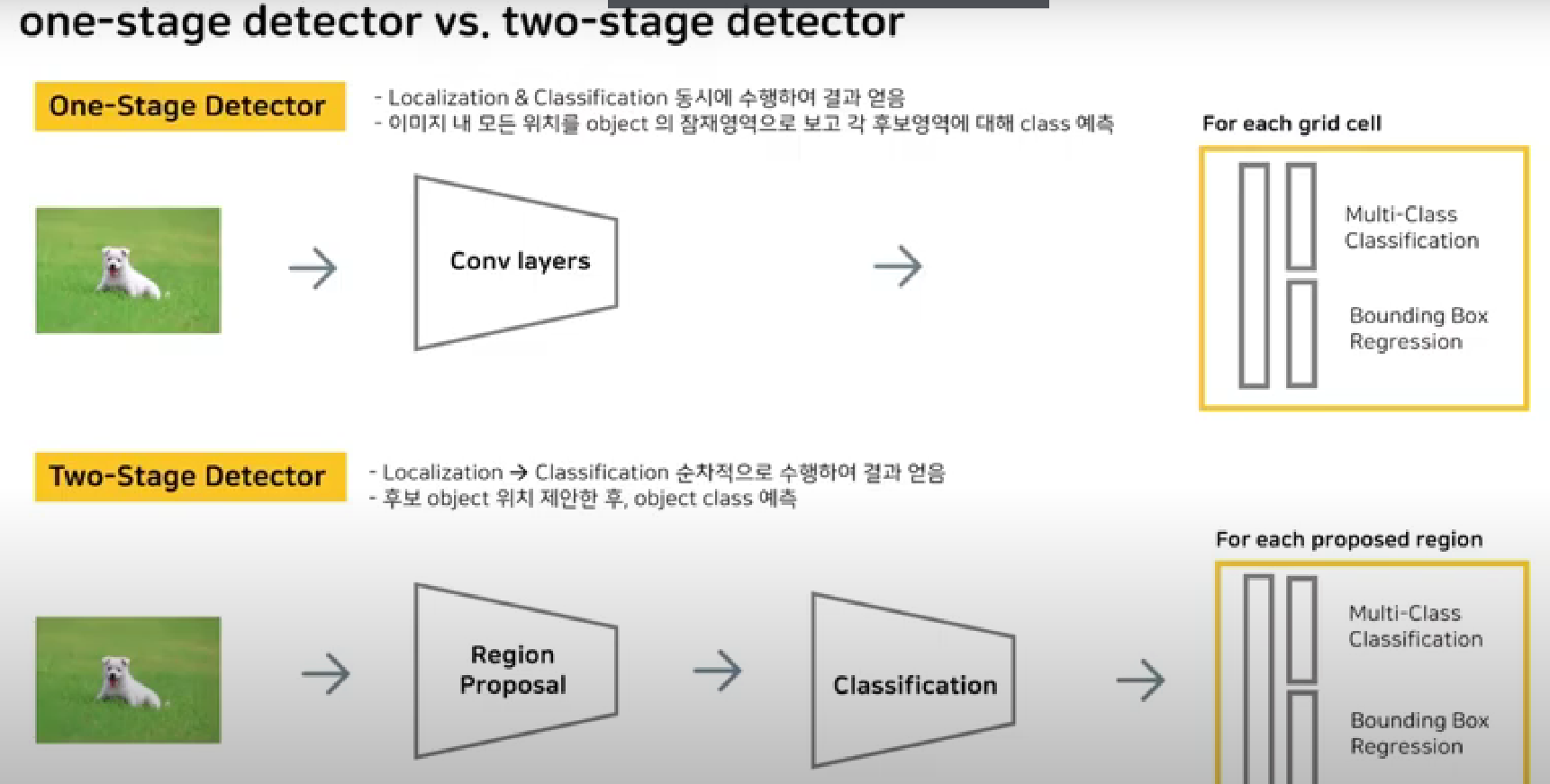
1-stage detactor
YOLO
object classification과 object localization을 동시에 수행
이미지 내 모든 위치를 object의 잠재영역으로 보고 각 후보영역에 대해 class 예측
이미지가 들어왔을 때 conv, fc 거친 후 reshape를 통해 output tensor 생성. 이후 알고리즘을 통해 classfication과 box 위치
속도 fast 정확도 낮음
2-stage detector
fast-RCNN
object localization 수행 후 object classification 수행
이미지 내 모든 위치가 아닌 후보 object 위치 제안한 후 object class 예측
reginal proposal 과정에서 물체가 가장 있음직한 proposed region 찾고 원본 이미지를 classification을 통해 feature maps 생성.
proposed region과 feature maps를 비율 맞춰 적절히 투영시켜서 결과값을 fc layer에 전달하고 이에 따라 classification과 box refinement를 가능하게 함
속도 slow 정확도 높음


논문 제목의 의미
You Only Look Once: 전체 이미지를 보는 횟수가 1회(1-stage), YOLO
Undefied: classification과 localization 단계 단일화
Real-Time: 기존 model에 비해 fast
Object Detection
Contribution
objcet detection을 regression problem으로 관점 전환
하나의 신경망으로 classification과 localization 예측 (unified architecture)
기존의 DPM, RCNN 모델보다 속도 개선
여러 도메인에서 object detection 가능
unified detection
기존 2-stage의 여러 단계를 1단계로 통합
이미지 전체를 통해 얻은 feature map으로 bbox와 class probability 계산을 병렬적으로 수행
예시

1. S=4, B=2, C=20
이미지를 S*S grid로 분할, 각 grid 마다 bbox B개씩 예측, 예측할 class 개수는 총 C개
2. 이미지 resize 후 4*4 grid로 분할
3. 각 grid마다 bbox 예측하여 (x,y,w,h,p) 출력
이때 x,y는 bbox의 중심좌표, w,h는 전체 이미지 크기에 대하여 bbox 크기를 나눈 normalize된 값(0~1사이)
c는 각 클래스에 대하여 bbox 내의 물체가 속할 확률을 의미

output tensor 구조의 원인
30 = 5*2 + 20
하나의 bbox에서 나오는 출력값 총 5개(x,y,w,h,p) * bbox 개수 2개 + 가능한 클래스의 개수 20개
yolo에서 사용한 network design

주로 사용한 모델의 구조 : goggleNet
총 20개의 conv 레이어는 tankless dataset이용해 pretrain
이후 4개의 conv layer과 2개의 fc레이어를 추가로 붙여 pascla에 대해 fine tunning 수행
conv 레이어 증가함에 따라 증가하는 연산량을 reduction layer 추가하여 연산량을 감소시킴
training stage
먼저 특정 object에 대해 responsible한 cell을 찾아야 함.
이는 GroundTruth box의 중심이 위치하는 grid cell로 할당
실제의 경우 bbox는 1개만 선정해서 사용
iou 값이 가장 높은 bbox를 선정하여 loss function에 반영



training stage의 loss function: MSE 이용

각 BBOX마다 Class specific confidence score 구함


bbox 개수 너무 많음 > NMS 알고리즘 적용
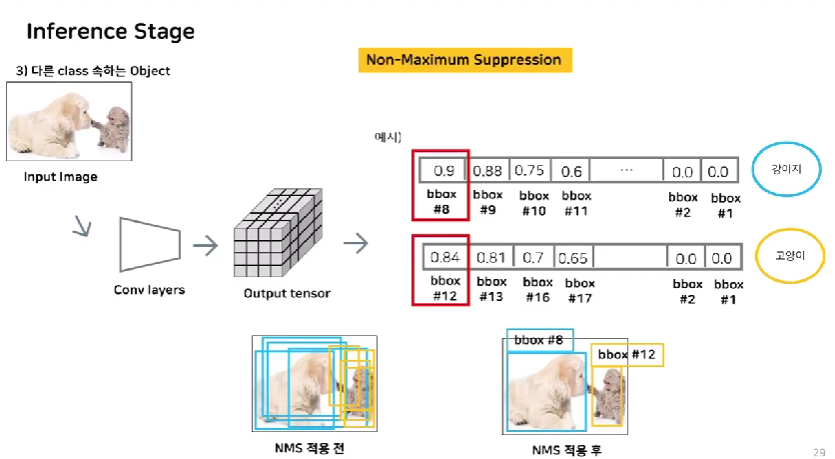
NMS(Non-maximum suppression)
각 object에 대해 예측한 bbox 중 가장 예측력 좋은 bbox만 남기기 위함
각 클래스마다 각각 적용하여 각각의 클래스에 대해 예측력이 좋은 bbox만 남김
#psuedo code
for i in range(len(class)):
if bbox['p_c'] < 0:
bbox_llist.remove(bbox)
while (not processed box exists):
selected_bbox = bbox with the highest p_c
bbox_list.remove[other boxes which has high IOU with selected bbox]
score sorting 후 특정 threshhold 값 이하인 경우 삭제
가장 score가 높은 bbox12 선택. bbox 12와 IOU가 높은 경우 삭제
IOU가 낮은 경우 서로 다른 물체를 탐지한다는 뜻. 제거하지 않음
실험
총 5가지의 실험 진행
PASCAL VOC 2007
Reference
You Only Look Once: Unified, Real-Time Object Detection
We present YOLO, a new approach to object detection. Prior work on object detection repurposes classifiers to perform detection. Instead, we frame object detection as a regression problem to spatially separated bounding boxes and associated class probabili
arxiv.org
'AI Theory' 카테고리의 다른 글
| [시계열 데이터] 1. introduction (0) | 2023.08.29 |
|---|---|
| [23.07.20.] 서울대학교 Data Science Day Review (0) | 2023.07.21 |
| [Boostcourse beyond ai] Optimization (0) | 2023.05.31 |
| [boostcourse beyond ai] Nueral Network (0) | 2023.05.29 |


