[Paper Review] Donut : Document Understanding Transformer without OCR
논문 선택 이유
영수증 사진 OCR 프로젝트를 진행하면서, pyclovaocr 라이브러리의 모델에 대해 공부하였고 관련 논문을 함께 공부하였다.
[Paper Review] What Is Wrong With Scene Text Recognition Model Comparisons? Dataset and Model Analysis (2019)
What Is Wrong With Scene Text Recognition Model Comparisons? Dataset and Model Analysis (2019) 이 논문을 공부하게 된 계기 AI 커뮤니티인 딥다이브의 object detection 스터디에 참여했다. 프로젝트도 하기로 했다. ocr을 이
itmaster98.tistory.com
그런데 위의 논문을 읽으면서, 모델이 실생활 이미지 속 텍스트를 인식하는 것까지는 설명되었으나 해당 텍스트 중 유효한 내용만을 추출하는 방법에 대해서는 알 수 없었다.
예를 들어 설명하자면 영수증 사진에는 제품명과 가격 외에도 다양한 텍스트가 존재하는데, 텍스트 인식을 수행할 경우 이러한 텍스트들 중 가격정보, 제품명과같이 유의미한 데이터만을 추출하는 프로세스가 별도로 필요한 것이다.

abstract
딥러닝 기반 OCR(Optical Character Recognition)의 발전을 기반으로 VDU(Visual Documnet Understanding) 시스템이 설계되었다.
이러한 OCR기반 접근 방식은 성능은 좋지만 높은 계산비용과 OCR Error Propagation으로 인한 성능저하와 같은 문제점이 있다.
이 논문에서는 OCR을 사용하지 않고도 end-to-end 학습이 가능한 새로운 VDU 모델을 제안한다.
이를 위해 모델을 사전 교육하는 새로운 작업과 합성 문서 이미지 생성기를 제안한다.
이러한 접근방식은 공개 벤치마크 데이터셋과 개인 산업 서비스 데이터셋을 이용한 다양한 문서 이해 작업에서 높은 성능을 달성하였다.
intro
VDU는 다양한 형식과 레이아웃, 내용에 상관없이 문서 이미지를 이해하는 것을 목표로 하는 task이며, 문서 처리 자동화를 위해 필수적인 task이다.
VDU는 후에 문서 분류, 구문 분석, 시각적 질문 답변 등에서 응용이 가능하다.
딥러닝 기반 OCR의 발전으로 인하여, 현재 대부분의 VDU 시스템은 OCR 모듈에 의존하여 이미지에서 텍스트 정보를 추출한다. 텍스트 탐지, 텍스트 인식, 구문분석 세 단계를 위해 3개의 개별 모듈로 전체가 구성되어 있다.
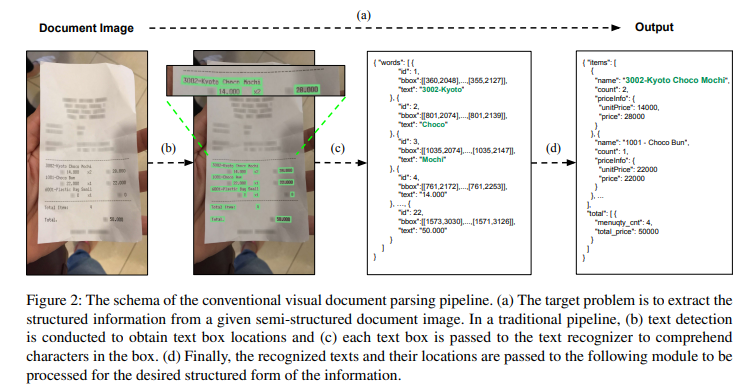
그러나 이러한 구조는 2가지 문제점이 있다.
1. OCR을 사용하는 것은 비용이 높음
자체적으로 OCR 모델의 학습을 위해서는 광범위한 감독과 대규모 데이터셋, GPU를 필요로 하는데 이는 비용이 많이 든다. 비용을 줄이기 위해 상용 OCR 엔진을 사용할 수도 있으나 항상 가능한 것이 아니며 목표 도메인에서의 엔진 성능이 저하될 수 있다.
2. OCR의 오류는 후속 단계에 부정적 영향을 미침
이 문제는 타 언어에 비해 OCR이 상대적으로 어려운 한국어, 일본어 등 복잡하고 큰 문자 집합을 가진 언어에서 더 심각하다. 별도의 post OCR 보정 모듈을 구축하는 것도 옵션이 될 수는 있으나 이는 전체 시스템의 크기와 비용을 증가시키기 때문에 실용적이지 않다.
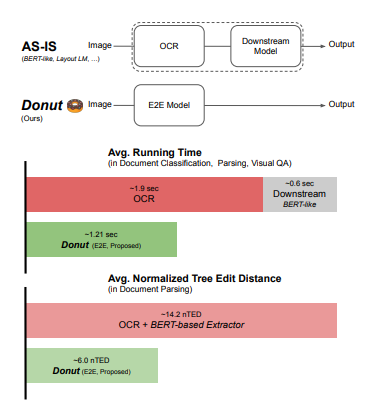
따라서 이 논문에서는 위의 문제점들을 극복할 수 있는 새로운 모델, Donut을 제시하고, 합성 문서 생성기인 SynthDoG와 pre-training task에 대한 적용도 제안한다.
Donut은 시각적 문서 이해를 위한 새로운 접근법으로, raw input에서 원하는 출력으로 매핑을 직접 모델링하는데, 이는 end-to-end 학습이 가능하고 다른 모듈에 의존하지 않는다. 또한 학습된 OCR이 없는 transformer 아키텍처 기반의 첫 방법론이다.
합성 문서 생성기인 SynthDoG의 경우 대규모 실제 문서 이미지에 대한 의존성을 완화시킬 수 있다.
이 논문은 위의 이러한 제안들에 대하여 광범위한 실험과 분석을 실시하여 제안들이 SOTA(현재 최고 수준의 결과)를 달성함을 보여줌과 동시에 이를 실제 애플리케이션에 반영했을 때의 실질적 이점에 대해서도 증명한다.
2. Method
이 챕터에서는 VDU를 위한 새로운 end-to-end 방법론으로서 Donut 제안
Donut은 input image를 구조화된 출력과 직접 매핑
2.1 background
영수증, 인보이스 등과 같은 반정형 문서에서 필수 정보를 이해하고 추출하기 위해 다양한 VDU 방법이 있었다.
VDU 초기에는 비전 기반 접근법, 이후 BERT의 등장으로 CV와 NLP 기술을 결합하기 시작하였다.
대부분의 최신 VDU 방법은 대규모의 실제 문서 이미지 데이터셋을 이용해 사전 교육한 별도의 OCR 엔진에 의존하는 구조로, OCR 엔진은 이미지에서 텍스트정보를 추출하며, 이 텍스트 정보는 원하는 내용만을 추출하는 다음 단계의 모듈로 전송된다.
2.2 Document Understanding Transformer(Donut)
이 논문에서는 위와 같이 OCR에 의존하지 않는, end-to-end 모델인 Donut(Document understanding transformer)을 제안한다. Donut은 시각적 인코더와 텍스트 디코더 모듈로 구성되며, 입력 문서 이미지를 원하는 구조의 형식으로 일대일 변환된 토큰 시퀸스와 직접 매핑한다.
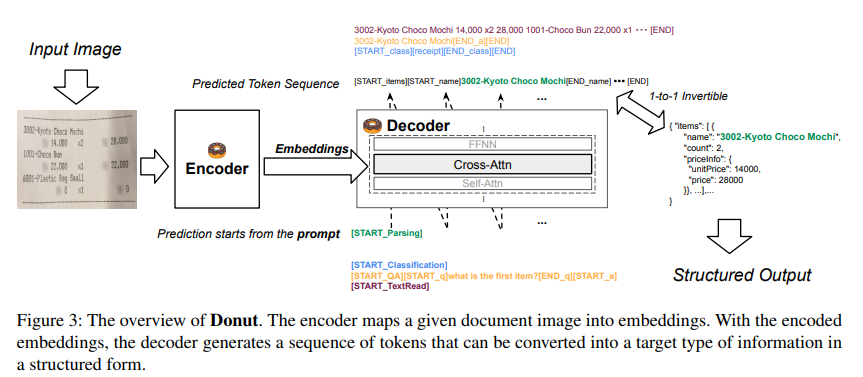
Encoder
입력 문서 이미지 $$ x∈R^(H×W×)C $$ 를 $ {zi |zi∈R^(d) , 1≤i≤n} $ 로 임베딩.
n은 feature map의 크기 또는 image patch의 수이고,
d는 잠재벡터(latent vector, 독립적인 잠재 변수들의 쌍)이다.즉 H*W*C 인 INPUT을 n*d 의 크기로 변환하는 것이다.이때 encoder로 CNN 기반 모델 또는 Transformer 기반 모델을 encoder network로 사용할 수 있다.이 논문에서는 구문분석의 SOTA를 달성한 Swin Transformer를 사용한다.
cf. 잠재 벡터?
딥러닝 ‘생성모델’과 ‘잠재 벡터’에 관하여
AI 아나운서 제작에 사용된 기술 중 딥러닝 생성모델 관련한 내용 관련 글
blog.est.ai
Decoder
encoder의 output인 {z}가 주어졌을 때, textual decoder는 토큰 시퀸스 $${
이 논문에서는 속도와 메모리를 고려하여 multilingual BART의 처음 4개 레이어를 decoder 아키텍처로 사용하였다.
Model Input
SynthDoG
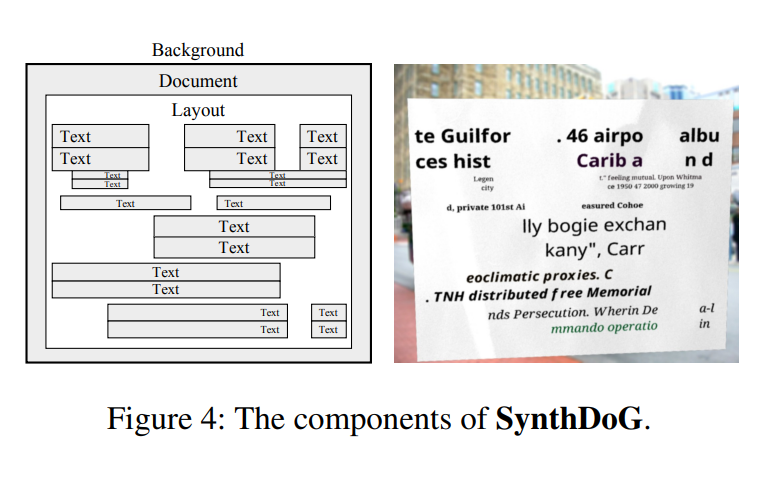
Background는 ImageNet에서, Document의 질감은 수집된 사진을 통해 샘플링된다.
또한 Text는 위키피디아에서, Layout은 규칙 기반 랜덤 패턴을 적용하여 실제 문서의 복잡한 레이아웃을 모방한다.
논문저자는 SynthDoG를 이용해 1.2M개의 합성 문서 이미지를 생성하였으며, 영어/한국어/일본어 위키피디아에서 추출한 단어를 사용해 언어당 40만개의 이미지를 생성하였고, 이미지의 텍스트를 왼쪽 위에서 오른쪽 아래로 읽도록 모델을 학습하였다.
2.4 application
모델이 읽는 방법을 학습한 뒤 애플리케이션 단계에서 모델은 주어진 문서 이미지를 이해하는 방법을 학습한다.
이 논문에서는 모든 다운스트림 작업을 json 예측 문제로 해석한다.
따라서 decoder는 원하는 output을 나타내는 json을 생성하도록 학습
3. experiment
3.1 실험내용
Document classification
모델이 문서 유형을 이해하는지 확인하기 위한 문서 classifcation task 수행
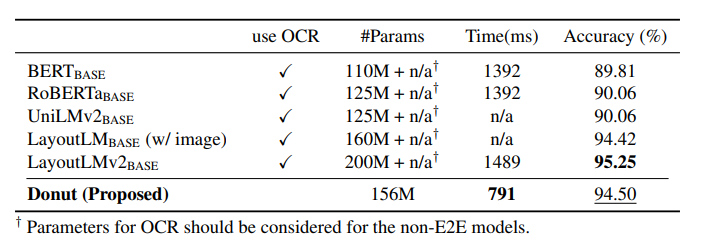
그 결과 기존의 SOTA 모델과 비교해도 높은 속도와 성능을 보여준다.
Document parsing
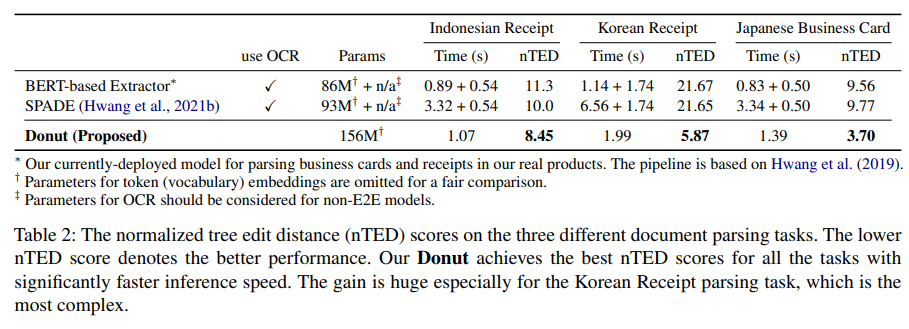
모델이 문서의 내용을 잘 이해하고 있는지 보기위해 Document parsing 진행.
times와 nTED(normalized Tree edit distance)를 기준으로 기존 baseline model과 비교하여 평가.
그 결과 Donut은 가장 높은 nTED 점수 보여줌
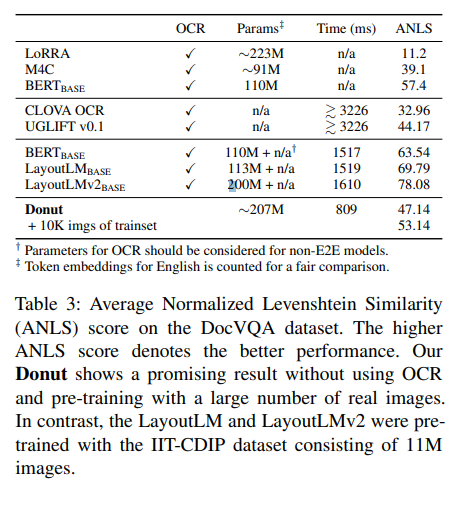
Document VQA
VQA에서는 문서이미지, 자연어 질문이 모델에게 주어지며 visual, textual 정보를 사용해 적절한 답을 예측해야 함. 평가지표는 ANLS로, average normalized levenshetein similarity이다. 결과는 아래와 같다.
참고자료
논문 다운로드 링크
https://arxiv.org/pdf/2111.15664v1.pdf
구현 코드
https://github.com/clovaai/donut
GitHub - clovaai/donut: Official Implementation of OCR-free Document Understanding Transformer (Donut) and Synthetic Document Ge
Official Implementation of OCR-free Document Understanding Transformer (Donut) and Synthetic Document Generator (SynthDoG), ECCV 2022 - GitHub - clovaai/donut: Official Implementation of OCR-free D...
github.com
잠재 벡터?
딥러닝 ‘생성모델’과 ‘잠재 벡터’에 관하여
AI 아나운서 제작에 사용된 기술 중 딥러닝 생성모델 관련한 내용 관련 글
blog.est.ai
