What Is Wrong With Scene Text Recognition Model Comparisons? Dataset and Model Analysis (2019)
이 논문을 공부하게 된 계기
AI 커뮤니티인 딥다이브의 object detection 스터디에 참여했다. 프로젝트도 하기로 했다.
ocr을 이용한 영수증 ocr을 주제로 정했다.
EasyOCR, CRAFT 등 여러 OCR 모델을 돌려본 결과 성능이 좋지 않았고, 짧은 프로젝트 기간을 고려하여 모델을 직접 손대는 것 대신, 네이버에서 비공식적으로 지원하는 라이브러리인 pyclovaocr을 이용해 프로젝트를 구현하기로 결정했다.
프로젝트를 99% 견인하는 완성된 라이브러리를 사용하는 대신에 해당 모델에 대한 심도깊은 공부를 하기로 했고, clova-ai가 CVPR 컨퍼런스에서 공개한 두 논문을 각자 하나씩 공부해오기로 했다.
논문의 목적
최근 Scene text recognition(STR)에 대해 다양한 방식이 도입되었으나, 훈련 및 평가 데이터세트의 일관성없는 선택으로 인해 STR에 대한 전체론적이고 공정한 비교가 누락되었다.
이 논문에서는,
1. 훈련 및 편가 데이터세트의 불일치로 인한 성능차이 조사
2. 대부분의 기존 STR를 통합한 4단계 STR 프레임워크 제시
3. 하나의 데이터셋을 기준으로 여러 모듈의 성능 기여도를 accuracy, speed, memory 측면에서 분석
를 통해 존재하는 STR 모듈들의 성능을 비교하고, 최적의 모듈 조합을 제시하며, STR 분야에서의 향후 연구 과제에 대해 제안하고 있다.
Scene Text Recognition(STR)이란?
기존의 전통적 OCR의 경우, 일반적으로 문서의 글자를 인식하는 TASK를 의미한다.

따라서 흰 종이 검은 글자처럼 한가지 색의 배경과 글자를 가진 제한된 환경인 경우가 많았다.
STR은 이러한 전통적 OCR의 한계를 넘어 일상생활 속 글자, 예를 들어 길가의 간판 등과 같은 복잡한 배경의 OCR을 하고자 하는 TASK이다.
STR의 경우 기울어지거나 굴곡된 이미지가 INPUT인 경우가 많아 직사각형 형태의 bbox로는 충분하지 않은 경우가 많다.
STR의 단계
- Scene Text Detection
- input 이미지 속 글자가 있는 영역 탐지
- 대표 모델
- EAST
- TextFuseNet
- Scene Text Recognition
- 글자가 있는 영역의 글자 인식
- 주로 RNN계열 모델 사용
- CRNN
- Yet Another Text Recognizer
- Text Spotting(End-to-End Scene Text Detection & Recognition)
- EAST와 CRNN 모델을 하나로 합친 모델로 연산 시간이 매우 짧다.
서론
STR은 다양한 산업 전반에서 중요하게 사용할 수 있다.
OCR의 발전은 문서로 잘 정리되어 있으나 이러한 전통적 OCR은 실제 산업 및 사회에서 사용하기에는 한계가 있다.
이러한 문제를 해결하고자, 이전 연구들에서는 각 stage에서 심층신경망을 사용한 multi-stage pipelines를 제안하였다.
예를 들어 shi et al은 다양한 문자를 처리하기 위해 순환 신경망을 사용하고
문자수 식별을 위해 connectionist temporal classification loss를 사용할 것,
input을 straight text image로 normalize하기 위한 transformation module을 제안하였다.
그러나 이렇게 새롭게 제안된 것들이 현재 어떠한 개선을 이루어냈는지를 평가하기는 어렵다.
기존의 논문들이 서로 다른 train dataset, evaluation datasets를 사용한 수치를 제공하고 있고, 이를 통해 비교하기는 어렵기 때문이다.
데이터셋의 차이가 모델 성능에 얼마나 큰 영향을 미치는지를 예를 들자면,
train dataset과 evaluation dataset을 결정할 때 동일한 IC13 데이터셋의 서로 다른 subset을 사용하였는데, 그 결과 15% 이상의 성능 차이가 발생하기도 하였다. 이렇듯 데이터셋의 불일치는 서로 다른 모델 간 성능 비교를 방해한다.
이 논문에서는 이러한 데이터셋 불일치 문제를 3가지 방법을 통해 해결한다.
- STR 논문에서 일반적으로 사용되는 모든 데이터셋 분석
- 기존 방식에 대한 공통적 관점을 제공하는 STR framwork 소개
- 기존 STR모델: 변환(Transformation), 특징추출(feature extraction), 모델링, 예측의 4가지 연속적 작업 단계
- 새로운 STR Framework에서는 기존의 방법뿐만 아니라 모듈별 기여도에 대한 분석을 위한 가능한 변형 제공
- 통합된 실험 설정에서 accuracy, speed, memory 측면에서 모듈별 기여도를 연구
- 개별 모듈에 대한 엄격한 평가와 새로운 모듈 조합 제안
- 실패 사례 분석을 통한 STR의 문제점 발견
그럼 아래 본문에서 자세한 내용을 살펴보자.
2. Dataset matters in STR
STR 연구들에서 지금껏 사용한 training, evalution datasets은 불일치하는 경우가 많으며 이로 인한 모델별 성능 평가가 어려운 상황이다.
먼저 STR연구에서 사용한 데이터셋의 종류들에 대해 알아보자.
STR에서 사용한 데이터셋은 크게 Synthetic datsets와 Real-world datasets 로 나뉜다.
Synthetic datsets는 컴퓨터가 합성을 통해 제작한 텍스트 데이터셋으로, 모델 훈련에 사용되는 데이터셋이다.
Real-world datasets은 실제 현실세계의 한 장면 속 텍스트 데이터셋으로, 모델 평가를 위해 사용된 데이터셋이다.
더 자세한 설명은 다음과 같다.
2.1 Synthetic datasets for training: 학습을 위한 합성 데이터셋들
- STR 모델을 train 시킬 때에는 label이 지정된 데이터를 얻기 어렵다.
- scene text image 데이터에 labeling을 하는 것은 비용이 많이 들기 때문이다.
- 따라서 대부분의 STR 모델에서는 train을 위해 합성 데이터셋(synthetic datasets)를 사용한다.
- 최근 논문에서 자주 사용되며, 인기있는 합성 데이터셋은 MJSynth, SynthText 데이터셋이다.

| MJSynth(MJ) | SynthText(ST) |
| ● STR용으로 설계된 합성 데이터셋 ● 890만개의 word box image를 포함 ● word box 생성과정 : 글꼴 렌더링 → 테두리 및 그림자 렌더링 → 배경 색상 지정 →글꼴, 테두리, 배경 구성→투명 왜곡 적용→실제 이미지와 혼합→노이즈 추가 |
● 원래는 Scene text Detection을 위해 생성된 합성 데이터셋 ● Scene text Detection를 위해 설계되었으나 이미지1의 (b)처럼 word box 부분만 잘라서 STR에 사용 ● 550만개의 훈련데이터 존재 |
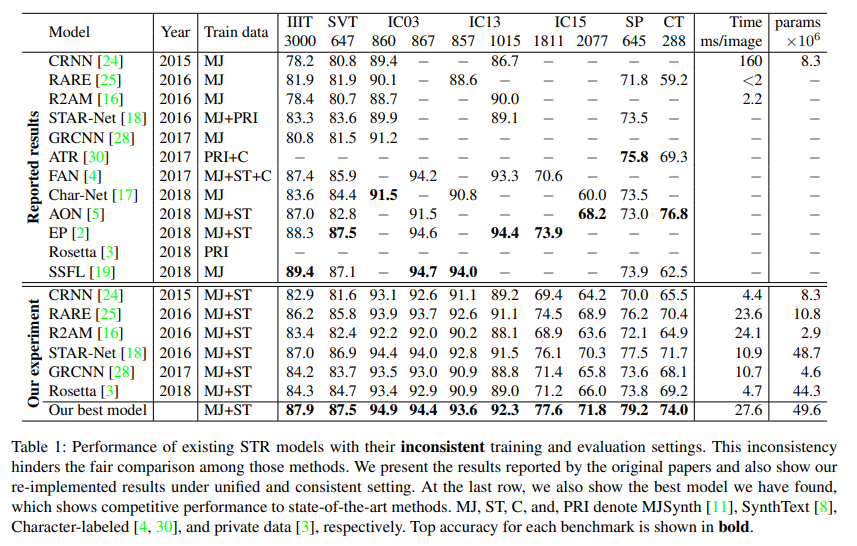
표1에서 확인할 수 있듯이, 과거 연구에서는 MJ, ST 및 다른 데이터셋을 이용해 다양한 조합의 데이터셋을 만들어서 사용하였다.
이러한 사용 데이터셋의 불일치는 기존의 연구 결과가 모듈의 개선으로 인한 것인지, 훈련 데이터의 변화로 인한 것인지에 대한 판단을 어렵게 했다.
따라서 이 논문에서는 향후 STR 연구에서 사용된 traindataset을 명확히 표시하고 동일한 trainset을 이용해 모델을 비교할 것을 제안하였다.
훈련데이터셋의 영향에 대한 자세한 내용은 4.2에서 확인!
2.2 Real-world datasets for evaluation: 평가를 위한 실제 데이터셋들
STR 모델의 evaluation을 위해서는 7개의 데이터셋이 널리 사용되고 있다.
과거 연구의 경우 사용한 데이터셋의 종류도 7개로 많을 뿐더러, 데이터셋의 서로 다른 하위집합이 evalutaion을 위해 사용되기도 하였다. 이러한 evaluation datset의 차이로 인하여 모델 간 비교에 일관성이 부족하였다.
표 1의 IC03 데이터셋만 봐도, 7개의 이미지 데이터 차이로 성능 차이가 발생하고 있음을 확인할 수 있다.
즉 모델 평가에 있어 다양한 데이터셋의 사용은 해결해야 하는 중요한 문제라고 볼 수 있다.
벤치마크 데이터셋은 텍스트 난이도와 기하학적 레이아웃에 따라 regular datset과 irregular dataset으로 나뉜다.

- Regular datasets
- 가로로 배치된, 문자 사이 간격이 균일한 텍스트 이미지
- STR에서 상대적으로 쉬운 사례들
- IIIT5K-Words (IIIT)
- Google image 검색에서 크롤링한 데이터셋
- 학습용 이미지 2000개와 평가용 이미지 3000개로 구성
- Street View Text (SVT)
- Google streetview에서 수집한 이미지
- 야외 거리가 포함된 이미지
- 노이즈와 흐림 존재, 해상도 낮음
- 학습용 이미지 257개, 평가용 이미지 647개로 구성
- ICDAR2003 (IC03)
- 카메라 사진 내 텍스트 읽기 대회인 ICDAR 2003 대회를 위해 만들어진 데이터
- 학습용 이미지 1156개, 평가용 이미지 1100개로 구성
- 3자 미만, 영숫자가 아닌 문자를 제외할 경우 평가용 이미지 수는 867개로 감소.
- 실제 연구에서 연구자들은 2가지 버전의 데이터셋 사용
- 평가용 데이터셋이 860개인 경우
- 평가용 데이터셋이 867개인 경우
- ICDAR2013 (IC13)
- 대부분 IC03에서 가져온 이미지 데이터셋
- ICDAR2013 대회를 위해 만들어짐
- 학습용 이미지 848개, 평가용 이미지 1095개로 구성
- 영숫자가 아닌 문자 제외시 평가용 이미지는 1015개로 감소
- ICDAR 2003 데이터셋과마찬가지로 연구자들은 두가지 버전의 데이터셋 사용,
- 3자 이내의 단어, 영숫자가 아닌 문자 제거한 857개와
- 영숫자 아닌 문자만을 제외한 1015개
- Irregulart datasets
- 굽어지거나 회전, 왜곡된 텍스트의 경우
- ICDAR2015 (IC15)
- ICDAR2015를 위해 만들어진 데이터셋
- 훈련용 이미지 4468개, 평가용 이미지 2077개
- 연구자들이 2가지 버전의 데이터셋 사용
- 평가용 이미지가 1811개인 버전: 영숫자가 아닌 이미지, 회전이나 구부러짐 정도가 심한 이미지를 제거
- 평가용 이미지가 2077개인 버전
- SVT Perspective (SP)
- Google Street View에서 수집한 데이터셋
- 평가용 이미지 645개 포함
- 대부분의 이미지가 non-frontal viewpoints의 보급으로 인한 perspective projections을 포함하고 있음
- CUTE80 (CT)
- 자연적으로 찍힌 사진에서 수집한 데이터
- 평가용 데이터 288개로 구성
- 대부분 이미지가 구부러진 텍스트 이미지
3. STR Framework Analysis
독립적으로 제안된 각 STR 모델 간 공통점을 추출하여 4단계로 구성된 STR 프레임워크를 소개
STR은 Computer Vistion, Sequence Prediction task와 유사하기 때문에, CNN, RNN을 통해 좋은 성능을 낼 수 있다.
CRNN은 STR 목적으로 만들어진 모델로, RNN과 CNN의 결합 응용 프로그램이다.
CRNN(Convolutional-Recurrent Neural Network)
CRNN은 STR 목적으로 만들어진 모델로, RNN과 CNN의 결합 응용 프로그램이다.
주어진 텍스트 이미지에서 CNN feature를 추출 후, 이 features를 RNN을 통해 sequence prediction을 수행한다.
CRNN의 등장 이후에도 STR의 성능 향상을 위한 여러 제안이 존재
- 다양한 모양의 text 형상을 사각화(rectify)하기 위한 텍스트 이미지 정규화 모듈: RARE, Star-net 등
- 글꼴스타일 및 어수선한 배경을 가진 복잡한 텍스트 이미지(높은 고유 차원 및 잠재요소 존재) 처리를 위한 개선된 CNN feature extractor: R2AM, Gated-RCNN, FAN 등
- 몇몇 방식은 RNN을 생략하기도 함: Rosetta
- Character sequence prediction 성능 개선을 위한 attention based decoder: R2AM, RARE
이러한 SRT 모델들을 참고하여 이 논문에서는 STR의 4-stage를 새롭게 제안하였다.
기존 STR 모듈들로부터 도출된 4-stage
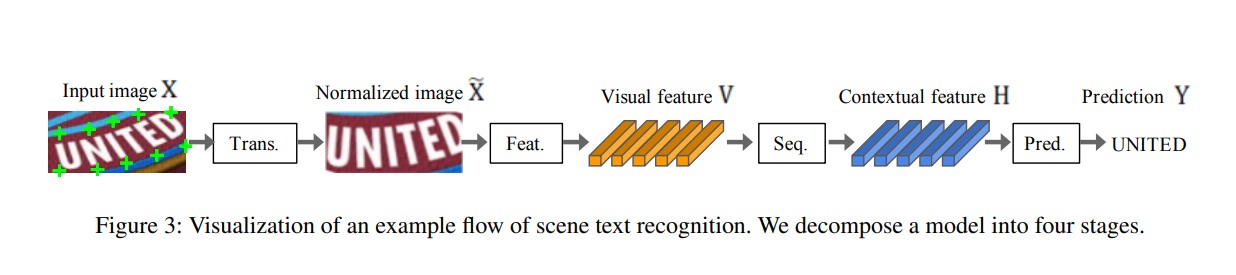
3.1 Transformation stage(Trans.): TPS, None
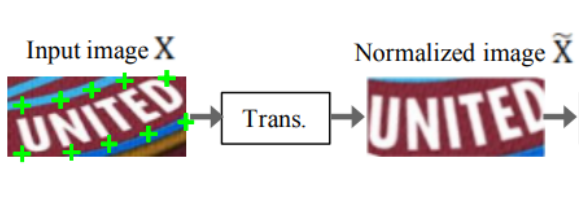
- Spatial Transforer Network(STN) 사용해 input text image X를 정규화된 이미지 X˜로 변환
- 실생활 속 텍스트 이미지는 대부분 휘어지거나 기울어진 형태이며 이러한 입력 이미지가 공급될 경우 이후의 단계인 feature extraction에서 이러한 형상들에 대한 invariant representation을 학습해야 함
- 이러한 부담을 줄이기 위해 STN의 변형인 TPS(thin-plate spline) 사용.
- 이미지3의 첫번째 사진의 녹색 + 표시가 TPS에 의해 발견된 fiducial points이며, TPS는 이를 기준점으로 문자 영역을 predefined rectangle로 정규화함
TPS에 대한 자세한 설명글
3.2 Feature extraction stage(Feat.): VGG, RCNN, ResNet
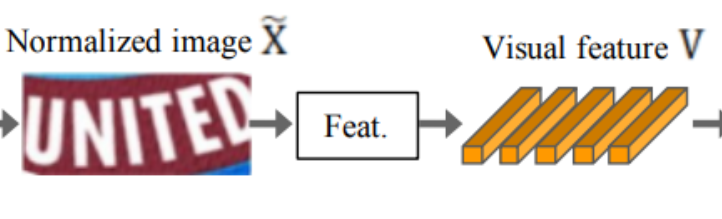
- 글꼴, 색상, 크기 및 배경 등과 같이 관련 없는 특징을 억제하고 문자 인식과 관련된 features에 초점을 맞춘 representation으로 이미지 매핑
- 입력 이미지인 X 또는 X˜를 CNN을 이용해 추상화하여 visual feature map V= {vi | i=1,...l} 형태의 output 생성
- visual feature map V란?
- eature extractor의 결과인 feature map을 column 별로 나눈 셋
- 각 column에는 입력 이미지의 수평 라인을 따라 해당하는 구별 가능한 receptive field가 존재.
- column별로 나누어 해당하는 receptive field 상의 character 예측
STR의 feature extractor로서는 VGG, RCNN, ResNet 이용
- VGG: 여러개의 Convolutional layers와 몇개의 fully connected layers로 구성된 모델
- RCNN: 문자 모양에 따라 수용 필드를 조정하기 위해 재귀적으로 적용가능한 CNN의 변형 모델
- ResNet: 다른 모델과 비교시 상대적으로 더 깊은 CNN 학습을 용이하게 하는 residual connection이 존재하는 CNN
3.3 Sequence modeling stage(Seq.): None, BiLSTM
- 다음 단계에서 각 문자를 예측할 수 있도록 문자 시퀸스 내 문맥적 정보(contextual information)를 학습하여 다음 단계에서 각 문자를 더 robust하게 예측할 수 있게 하는 단계
- 이전 단계의 visual feature map V의 각 column은 sequence 형태로 사용되지만, contextual information이 부족
- 따라서 이 단계인 Seq 에서는 더 나은 시퀸스 H = Seq.(V)를 만들기 위해 BiLSTM(Bidirectional LSTM) 사용
- BiLSTM는 계산 복잡도, 메모리 소비를 높일 수 있으므로 프레임워크에서 on/off 가능
3.4 Prediction stage(Pred.): CTC, Attn
- 이미지의 identified features로부터 출력할 character sequence 추정
- 이전 단계에서 입력받은 H로부터 character sequence 예측
- 두 종류의 예측 옵션 존재: CTC, Attn
- 연결주의 시간 분류(CTC, connectionist temporal classification)
- H의 각 열 h_i에 대하여 문자를 예측하고 반복되는 문자와 공백을 삭제하여 전체 문자 시퀸스를 가변 길이의 stram of characters로 수정
- 고정된 수의 feature가 제공되더라도 고정되지 않은 수의 시퀸스 예측 가능
- 주의 기반 시퀀스 예측(Attn, attention-based sequence prediction)
- 입력 시퀸스 H의 정보 흐름을 자동으로 파악하여 output sequence 예측
- output class에 대한 종속성을 나타내는 문자 수준 언어 모델 학습가능
- 연결주의 시간 분류(CTC, connectionist temporal classification)
4. Experiment and analysis
STR 모델의 가능한 모든 조합인 24개(2*3*2*2)의 조합에 대한 평가 및 분석
4.1 Implementation detail
훈련 데이터셋, 평가 데이터셋은 STR 모델의 성능 측정에 영향을 미치므로 training, validation, and evaluation datasets의 선택에 대해 수정하였다
- 사용한 STR training dataset
- 기존 trainset의 합집합 사용
- MJSynth 8.9M + SynthText 5.5M(총 14.4M)의 합집합
- 감쇠율이 ρ = 0.95로 설정된 AdaDelta 옵티마이저를 채택
- 배치 사이즈: 192
- 반복 횟수: 300K
- Gradient clipping: size 5
- 모든 매개 변수는 He의 방법으로 초기화
- validation dataset과 model selection
- IC13, IC15, IIIT 및 SVT
- 2000개의 훈련 단계마다 모델을 검증하여 이 세트에서 가장 높은 정확도를 가진 모델을 선택
- IC03 기차 데이터가 포함되어 있지 않으나, IC03 데이터셋의 일부가 IC13 데이터셋에 존재하므로 겹치는 데이터가 존재함. 복제된 장면 이미지의 총 수는 34개이며, 215개의 단어 상자가 포함
- 모델 평가지표
- accuracy, speed, memory 관점에서 STR의 조합 평가
- 알파벳과 숫자 데이터로만 평가
- accuracy: 벤치마크 데이터셋의 모든 subset과 통합 평가데이터셋(총 8539 이미지)를 포함하는 testset에서 예측 성공률 측정. 각 str 조합에 대해 서로 다른 초기화 랜덤시드를 사용하여 5번의 시험 실행후 정확도 평균화
- speed: 동일한 컴퓨팅 환경에서 주어진 텍스트를 인식하기 위한 시간 측정
- memory: 전체 str 파이프라인에서 학습가능한 부동 소수점 매개변수 수 계산
4.2 Analysis on training datasets
서로 다른 train dataset 그룹이 성능에 미치는 영향 조사한 결과,
MJSynth 데이터셋만 사용했을 때는 80%의 정확도,
SynthText 데이터셋만 사용했을 때에는 75.6%의 정확도,
둘다 사용했을 때에는 84.1%의 정확도로 개별 사용시보다 정확도 4.1% 향상됨
즉, 서로 다른 훈련 데이터를 사용한 뒤 나온 모델 정확도로는 모델간 성능을 비교할 수 없다.
동일한 훈련 데이터셋으로 모델 학습한 결과
MJSynth(1.8M)의 20%와 SynthText(1.1M)의 20%(총 2.9M ≈ SynthText의 절반)을 사용한 결과 81.3%의 정확도
MJSynth와 SynthText는 왜곡 및 흐림과 같은 다른 옵션으로 생성되었기 때문에 속성이 다르다.
즉 위의 결과는 훈련 데이터의 다양성이 훈련 사례의 수보다 더 중요할 수 있으며, 서로 다른 훈련 데이터 세트를 사용하는 것이 데이터셋이 단순히 많은것보다 좋다는 결론보다 더 복잡하다는 것을 보여줌
4.3 Analysis of trade-offs for module combination: 모듈 조합에 대한 장단점 분석
다양한 모듈 조합에서 나타나는 정확도,속도,메모리 tradeoff를 분석

그래프에 ★로 표시된 점들은 이전에 제안되었던 모델들이다.
- time-accuracy 그래프에서 Rosetta와 STAR-Net은 선위에 있고 나머지 4개의 이전 모델들은 선 안에있다.
- parameter-accuracy 그래프에서 R2AM이 선위에 있고 나머지 5개 모델은 선안에 있다.
trade-off frontiers에 따른 조합 분석
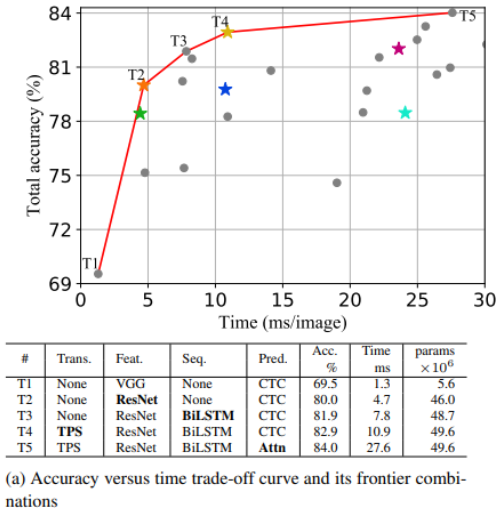
- time-accuracy 그래프를 살펴보면 T1은 Trans.와 Seq. 모듈을 포함하고 있지 않아 최소 시간이 소요된다.
- 그리고 T1에서 T5로 이동할수록, 표에서 굵게 표시된 모듈들, ResNet, BiLSTM, TPS, Attn 모듈이 순서대로 하나씩 도입되며 모델의 복잡성이 순차적으로 증가하고 있다.
이러한 과정에서
- ResNet, BiLSTM 및 TPS가 도입될 때까지 정확도는 69.5%에서 82.9%로 크게 증가하지만, 속도 또한 1.3ms에서 10.9ms로 증가한다.
- 반면 마지막으로 추가된 Attn의 경우 82.9에서 84.0으로 정확도를 1.1%올리는데에 27.6-10.9 ms의 상대적으로 매우 높은 시간을 비용으로 소모한다.
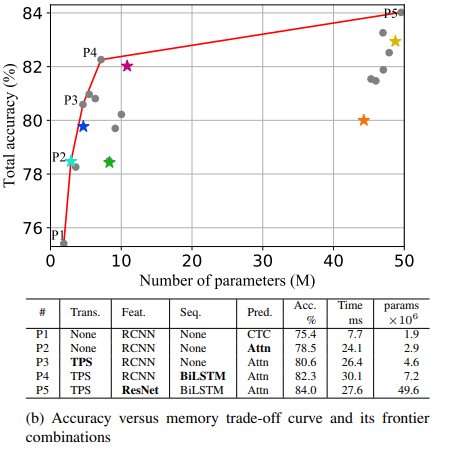
- 이미지 4(b)의 accuracy-memory tradeoff에서는 P1이 메모리 소모량이 가장 적은 모델이며, P1에서 P5로 갈수록 메모리 소모량이 증가, 정확도도 증가하는 tradeoff가 발생한다.
- 이전 실험에서와 마찬가지로 이번 실험에도 Attn, TPS, BiL STM 및 ResNet 모듈을 순차적으로 하나씩 도입시키며 메모리 비용을 순차적으로 높인다.
- 이전 실험의 T1에서 Feature extraction을 위해 사용한 VGG에 비해 RCNN이 더 가볍고 정확도와 메모리간 균형이 양호
- Trans, Seq, Pred 단계의 모듈이 메모리 소비에 크게 기여하지 않음:1.9M에서 7.2M로 전반적으로 가볍지만 정확도 향상에 기여(75.4%에서 82.3%)
- 최종 변경 모듈인 P5의 ResNet의 경우, 메모리 소비가 7.2M에서 49.6M로 크게 증가하였는데 정확도는 1.7%만 증가
- 실무에서 trans, seq, pred 단계에서는 비교적 자유롭게 모듈 선택이 가능하지만 feat에서 resnet과 같은 무거운 feature extractor 사용하는 것에 주의할 것
speed와 memory 측면에서 가장 중요한 모듈?
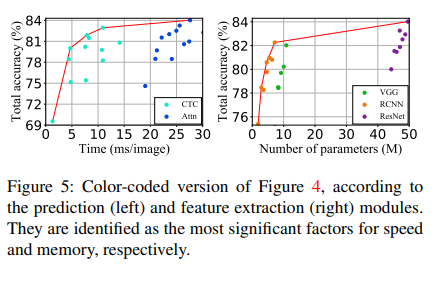
그렇다면 각각의 그래프에서 가장 큰 영향을 미치는 단계는?위의 이미지4에서 주어진 그래프르 color coding한 결과, 이미지 5에서 확인할 수 있듯이 확실한 클러스터가 나왔다.
- 이미지 5의 그래프에 의하면 time-accuray에 가장 큰 영향을 미치는 단계는 Pred 단계, memory-accuracy에 가장 큰 영향을 미치는 단계는 Feat 단계라고 볼 수 있다.
- Pred 단계에서 CTC 대신 Attn을 사용하면 속도가 느려지고, Feat 단계에서 ResNet을 사용할 경우 메모리 사용량이 가장 크며 RCNN의 메모리 사용량이 가장 적은 것을 확인할 수 있다.
4.4 Module analysis
accuray, momory, speed 측면에서 모듈별 성능을 분석
이때 각 모듈의 accuracy는 아래와 같은 조합을 평균화하여 계산
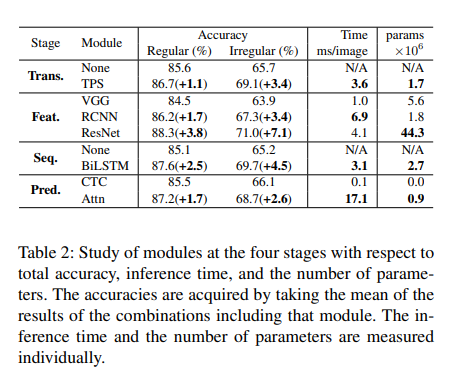
각 단계에서 모듈의 성능을 향상시키기 위해서는 추가 메모리와 시간이 필요하다.
모든 단계에서 irregular dataset을 사용했을 때의 성능 향상이 regular dataset 사용시보다 약 2배 증가
time 사용량을 고려한 accuracy 향상을 원할 경우, 가장 빠른 조합은 None-VGG-None-CTC 조합이며,
ResNet, BiLSTM, TPS, Attn을 순서대로 추가할 경우 시간순대로 모듈 업그레이드가 가능하다. 이 순서는 이미지 4에서의 T1 -> T5 조합 순서와 동일하다.
메모리 사용량을 고려한 accuracy 향상을 원할 경우, 기본조합인 None-VGG-None-CTC 조합에서 RCNN, Attn, TPS, BiLSTM, ResNet 순서대로 추가하는 것이 가장 효율적인 순서이다.
흥미롭게도 메모리 사용량을 고려한 모듈 추가 순서와 시간을 고려한 모듈 추가 순서는 반대의 경향을 띄고 있다.
또한 두 관점에서의 모듈 순위는 프론티어 모듈 변경 순서와 동일하며, 이는 각 모듈이 모든 조합에서 유사하게 성능에 기여함을 보여줌
모듈의 정성적 분석
각 모듈에 대한 자세한 설명은 3을 참고
아래 이미지는 각 단계에서 모듈이 업그레이드 되었을 때에만 올바르게 인식되는 샘플들의 사례이다.
예를 들어 맨 위의 이미지 3개의 경우 Trans 단계에서 모듈을 사용하지 않았을 경우(None)에는 text인식에 실패하였으나, TPS 모듈을 사용하였을 경우 올바른 text인식에 성공하였다.

- Trans 단계에서 TPS 모듈은 곡선 및 원근 텍스트를 표준화한다.
- Feat 단계에서 ResNets은 기존 VGG보다 더 나은 feautre extractor로서 복잡한 배경 및 글꼴이 있는 경우를 개선한다.
- Seq 단계에서 BiLSTM은 수용 필드를 조정하여 더 나은 context modeling을 유도한다.
- 예를 들어 위의 사례에서 EXIT 끝의 잘린 문자, G20 끝의 잘린문자 C를 무시할 수 있다.
- Pred 단계에서 Attn은 암시적 문자 수준 언어 모델링을 포함하여, Hard, , to, House의 누락되거나 가려진 문자를 찾을 수 있다.
4.5 Failure case analysis
아래 사진은 이 논문에서 제안한 모든 24개 조합을 사용했음에도 분석에 실패한 사례들이다.

전체 벤치마크 데이터셋의 8539개 예시 중 7.5%인 644개의 이미지가 24개 모델 조합에서 바르게 인식되지 않았다.
그러한 사례들을 일반화하여 총 6가지로 나누었다.
(a) Diffult fonts
캘리그라피 글꼴과 같이 어려운 형태의 폰트를 가진 글자들
이러한 다양한 문자 표현의 일반화된 visual feature를 제공하는 새로운 feature extractor, 또는 정규화가 필요
(b) Vertical texts
대부분의 STR 모델은 가로 텍스트 이미지를 가정하고 있으므로 세로 텍스트를 처리할 수 없음.
일부 STR 모델에서 세로 텍스트 정보를 활용하기도 하지만 추가 연구 필요
(c) 특수문자(Special characters)
사용중인 벤치마크 데이터셋은 특수문자를 평가하지 않아 훈련중 특수문자를 제외함
이로인해 특수문자를 영숫자로 취급하도록 하는 오류 발생
특수문자 훈련을 추가한 결과 IIIT에서 정확도가 87.9%에서 90.3%로 향상됨
(d) Occlustion(폐색)
대상이 다른 물체에 의해 가려지거나 일부만 보임
현재의 모델들은 이를 극복하기 위해 contextual information을 사용하고 있지 않으며, 향후 연구에서의 고려 필요
(e) Low resolution(저해상도)
현재 모델에서 저해상도 사례를 명시적으로 처리하지 않음
이미지 피라미드, 초고해상도 모듈을 통해 성능향상 가능
(f) Label noise
잘못된 label(noise label) 존재.
모든 벤치마크 데이터셋을 확인한 결과 모두 noise label을 포함하고 있으며 구체적으로는
특수문자를 고려하지 않고 잘못 라벨링(1.3%)
특수문자를 고려하여 잘못 라벨링(6.1)
대소문자를 고려하여 잘못 라벨링(24.1%)
참고자료
추천! STR에 관하여 정리 완전 잘해두셨당.굿굿
https://neverabandon.tistory.com/60
[논문 읽기/2020] Text Detection and Recognition in the Wild: A Review
link: arxiv.org/pdf/2006.04305.pdf Abstract 자연 이미지에서 text를 detection하고 recognition 하는 것은 스포츠 비디오, 자율 주행, 산업 자동화 등의 다양한 분석에 적용되는 컴퓨터 비전 분야의 2가지 주요한
neverabandon.tistory.com
https://yongwookha.github.io/MachineLearning/2022-02-08-current-ocrs
논문 다운로드 링크
https://arxiv.org/pdf/1904.01906.pdf
논문 구현 GITHUB 링크
https://github.com/clovaai/deep-text-recognition-benchmark
GitHub - clovaai/deep-text-recognition-benchmark: Text recognition (optical character recognition) with deep learning methods.
Text recognition (optical character recognition) with deep learning methods. - GitHub - clovaai/deep-text-recognition-benchmark: Text recognition (optical character recognition) with deep learning ...
github.com
https://velog.io/@recoder/Scene-Text-Overview
[OCR] 거리&일상 이미지 속 텍스트 인식 - Scene Text Detection & Recognition
Scene Text Detection & Recognition - typical dataset & models
velog.io
'Paper Review' 카테고리의 다른 글
| [Paper Review] Donut : Document Understanding Transformer without OCR (1) | 2023.03.03 |
|---|
