비지도학습(Unsupervised Learning)
- 지도학습과 달리 training data로 정답(label)이 없는 데이터가 주어지는 학습방법
- 라벨링이 되어 있지 않은 데이터들 내에서 비슷한 특징이나 패턴을 가진 데이터들끼리 군집화한 후, 새로운 데이터가 어떤 군집에 속하는지를 추론한다.
- 군집화(클러스터링, clustering), 차원축소(dimensionality reduction) 등이 있다.
클러스터링(군집화)
- 명확한 분류 기준이 없는 상황에서 데이터들을 분석하여 가까운(또는 유사한) 것들끼리 묶어 주는 작업
- 개별적인 데이터들을 몇 개의 그룹으로 추상화하여 새로운 의미를 발견할 수 있다.
- 대표적으로 K-Means, DBSCAN 등이 있다.
K-Means
- k 값이 주어져 있을 때, 주어진 데이터들을 k 개의 클러스터로 묶는 알고리즘
- 임의로 지정한 k값이 label의 역할을 한다.
- 대표적인 클러스터링 기법 중 하나
- 일반적으로 성능이 뛰어나지만 주어진 데이터 분포에 따라 클러스터링 결과가 적절하지 않을 수 있다.
- 군집의 개수 k를 미리 예측하기 힘든 경우
- 데이터 분포에 따라 유클리드 거리가 멀면서 밀접하게 연관되어 있는 데이터를 군집화 하고 싶은 경우



K-means의 과정
1. 원하는 클러스터의 수 k 결정
2. 무작위로 클러스터 수와 같은 k개의 centroid 선정 (각 클러스터들의 대표)
3. 나머지 각각의 점들과 모든 centroid간 유클리드 거리(L2 distance) 계산 후, 각각의 점을 가장 가까운 거리를 갖는 중심점의 클러스터에 속하도록 함
4. 각 k개 클러스터의 centroid 재조정. 특정 클러스터에 속하는 점들의 평균값이 새로운 centroid가 됨
5. 새로운 centroid를 기준으로 3,4 반복(반복 횟수는 사용자가 결정)해서 centroid가 수렴되도록 함
sklearn을 이용한 k-means 구현
from sklearn.cluster import KMeans
# 클러스터 개수가 5개인 k means
kmeans_cluster = KMeans(n_clusters=5)
# 학습 진행
kmeans_cluster.fit(points)
print(type(kmeans_cluster.labels_)) # label의 type
print(np.shape(kmeans_cluster.labels_)) # label shape
print(np.unique(kmeans_cluster.labels_)) # label값의 종류
# n 번째 클러스터 데이터를 어떤 색으로 도식할 지 결정하는 color dictionary
color_dict = {0: 'red', 1: 'blue', 2:'green', 3:'brown', 4:'indigo'}
# 점 데이터를 X-Y grid에 시각화
fig = plt.figure()
ax = fig.add_subplot(1, 1, 1)
# K-means clustering의 결과대로 색깔별로 구분하여 점에 색칠한 후 도식
for cluster in range(5):
cluster_sub_points = points[kmeans_cluster.labels_ == cluster] # 전체 무작위 점 데이터에서 K-means 알고리즘에 의해 군집화된 sub data를 분리
ax.scatter(cluster_sub_points[:, 0], cluster_sub_points[:, 1], c=color_dict[cluster], label='cluster_{}'.format(cluster)) # 해당 sub data를 plot함
# 축 이름을 라벨에 달고, 점 데이터 그리기
ax.set_xlabel('X')
ax.set_ylabel('Y')
ax.legend()
ax.grid()

DBSCAN (Density Based Spatial Clustering of Applications with Noise)
- 군집의 개수를 명시하지 않으면서, 밀도 기반으로 군집을 예측하는 방법
- 가장 널리 알려진 밀도(density) 기반의 군집 알고리즘
- k means와 다르게 원 모양의 군집이 아닌 불특정한 형태의 군집도 찾을 수 있다.
- 클러스터가 최초의 점 하나로부터 점점 퍼져나가는 형태이다.

DBSCAN의 과정
- epsilon: 클러스터의 반경
- minPts: 클러스터를 이루는 개체의 최솟값
- core point: epsilon 내 minPts개 이상의 점이 존재하는 중심점
- border point: 군집에 속하지만 core point가 아닌 점
- noise point: 군집에 속하지 못한 점
DBSCAN 학습 전, 미리 epsilon과 minPts를 지정해주어야 한다.
1. 임의의 점 p를 설정하고, 주어진 클러스터 반경(epsilon) 내 p를 포함한 점들의 개수를 센다
2. 만약 해당 원에 minPts 개 이상의 점이 포함되어 있으면, p를 core point로 간주하고 epsilon 내의 점들을 하나의 클러스터로 묶는다.
3. 만약 해당 원에 존재하는 점의 수가 minPts 개 미만일 경우, 일단 pass 한다.
4. 모든 점들에 대해 1~3을 반복한다. 만약 새로운 점 q가 core point이고, 이미 클러스터에 속해 있다면 두 개의 클러스터를 하나로 합친다.
5. 모든 점에 대해서 1~4 반복했음에도 클러스터에 속하지 못한 점이 있으면 noise point로 간주한다. core point가 아닌 점들은 border point라고 정의한다.
scikit learn을 활용한 DBSCAN 구현
# DBSCAN으로 circle, moon, diagonal shaped data를 군집화한 결과
from sklearn.cluster import DBSCAN
fig = plt.figure()
ax= fig.add_subplot(1, 1, 1)
color_dict = {0: 'red', 1: 'blue', 2: 'green', 3:'brown',4:'purple'} # n 번째 클러스터 데이터를 어떤 색으로 도식할 지 결정하는 color dictionary
# 원형 분포 데이터 plot
epsilon, minPts = 0.2, 3 # 2)와 3) 과정에서 사용할 epsilon, minPts 값을 설정
circle_dbscan = DBSCAN(eps=epsilon, min_samples=minPts) # 위에서 생성한 원형 분포 데이터에 DBSCAN setting
circle_dbscan.fit(circle_points) # 3) ~ 5) 과정을 반복
n_cluster = max(circle_dbscan.labels_)+1 # 3) ~5) 과정의 반복으로 클러스터의 수 도출
print(f'# of cluster: {n_cluster}')
print(f'DBSCAN Y-hat: {circle_dbscan.labels_}')
# DBSCAN 알고리즘의 수행결과로 도출된 클러스터의 수를 기반으로 색깔별로 구분하여 점에 색칠한 후 도식
for cluster in range(n_cluster):
cluster_sub_points = circle_points[circle_dbscan.labels_ == cluster]
ax.scatter(cluster_sub_points[:, 0], cluster_sub_points[:, 1], c=color_dict[cluster], label='cluster_{}'.format(cluster))
ax.set_title('DBSCAN on circle data')
ax.set_xlabel('X')
ax.set_ylabel('Y')
ax.legend()
ax.grid()

K means와 다르게 원하는 대로 객체마다 잘 클러스터링 되는 것을 확인할 수 있다.
DBSCAN은 클러스터의 개수를 미리 정할 필요 없이 epsilon과 minPts 값을 잘 조절해주면 군집화를 진행할 수 있어 K MEANS보다 유연한 사용이 가능하다.
그러나 군집화할 데이터 수가 많을수록 수행 시간이 급격히 증가한다는 단점, 데이터 분포에 맞는 epsilon과 minPts를 지정해야 한다는 단점이 있다.

차원 축소(Dimensionality reduction)
- 비지도학습의 대표 방법 중 하나
- 수많은 정보 속에서 우리에게 더 중요한 요소가 무엇인지를 알게 해주는 방법
- 데이터를 나타내는 여러 특징(feature)들 중에서 어떤 특징이 가장 그 데이터를 잘 표현(represent) 하는지 알게 해주는 특징 추출(feature extraction)의 용도로 사용
- PCA, t-SNE 등이 있다.
PCA
- 데이터 분포의 주성분을 찾아주는 방법
- 주로 선형적인 데이터의 분포를 갖고 있을 때 PCA 수행 후 정보가 가장 잘 보존된다.
- 기존 feature 중 중요한 것을 선택하는 방식이 아닌 기존의 feature를 선형 결합(linear combination)하는 방식을 사용
- 주성분: 데이터의 분산이 가장 큰 방향벡터
- PCA는 데이터들의 분산을 최대로 보존하면서, 서로 직교(orthogonal)하는 기저(basis, 분산이 큰 방향벡터의 축)들을 찾아 고차원 공간을 저차원 공간으로 사영(projection)한다.
- 즉 데이터에서 분산이 가장 길게 나오는 기저(basis) 방향을 찾아서 그 방향의 기저만 남기고, 덜 중요한 기저 방향을 삭제하는 방식으로 진행된다.
- 이때 찾은 가장 중요한 기저(가장 분산이 큰 기저)를 주성분(Principle component)방향, 또는 pc 축이라고 한다.

위의 데이터의 두 벡터(기저, basis)를 새로운 좌표계로 변환하여 표현할 수 있다.
차원의 수는 줄이면서 데이터 분포의 분산을 최대한 유지하기 위해 가장 분산이 긴 축을 첫 기저로 잡고, 그 기저에 직교하는 축 중 가장 분산이 큰 값을 다음 기저로 잡는다. 이러한 과정을 반복하면 차원의 수를 최대로 줄이면서 데이터 분포의 분산을 그대로 유지할 수 있으며 이를 차원축소라고 한다.
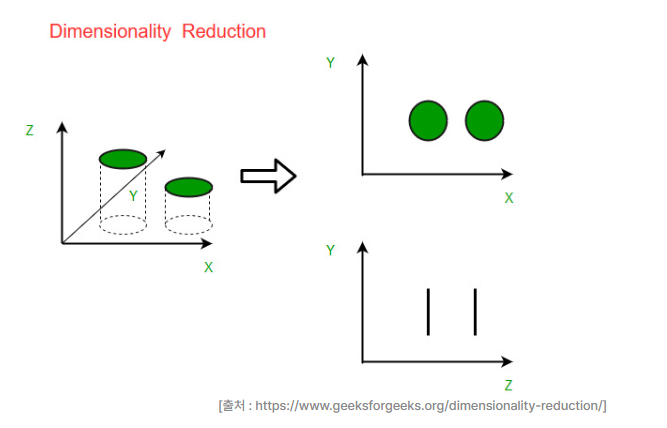
cf. X-Y-Z 좌표축상에 존재하는 데이터를 X-Y, Y-Z 좌표축에 사영(projection) 했다?
- 각각 Z, X 좌표축을 무시했다는 뜻 따라서 무시한 데이터만큼의 정보손실이 일어난다.
- 위의 사진의 X-Y-Z를 차원축소한 두 그림 중 원본 데이터를 더 잘 표현한 것은 직관적으로 봤을 때 X-Y 그래프 일 것이다.
- 따라서 Z축 방향의 정보는 X,Y 축의 정보에 비해 상대적으로 덜 중요하며, 수학적으로는 Z축 방향의 분산이 작다고 표현할 수 있다.
scikit learn을 활용한 PCA, SVC 구현
# IMPORT
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
from sklearn import svm
from sklearn.metrics import accuracy_score
from collections import Counter
#Train data에 PCA 알고리즘 적용
train_X_ = StandardScaler().fit_transform(train_X) # 불러온 데이터에 대한 정규화(range같게함)
train_df = pd.DataFrame(train_X_, columns=cancer['feature_names'])
pca = PCA(n_components=2) # 주성분의 수를 2개, 즉 기저가 되는 방향벡터를 2개로 하는 PCA 알고리즘 수행
pc = pca.fit_transform(train_df)
## PCA를 적용한 train data의 classifier 훈련: classfier로 Support Vector Machine(SVM) 사용
clf = svm.SVC(kernel = 'rbf', gamma=0.5, C=0.8)
clf.fit(pc, train_y) # train data로 classifier 훈련
#Test data에 PCA 알고리즘 적용
test_X_ = StandardScaler().fit_transform(test_X) # normalization
test_df = pd.DataFrame(test_X_, columns=cancer['feature_names'])
pca_test = PCA(n_components=2)
pc_test = pca_test.fit_transform(test_df)
## PCA를 적용하지 않은 original data의 SVM 훈련
clf_orig = svm.SVC(kernel = 'rbf', gamma=0.5, C=0.8)
clf_orig.fit(train_df, train_y)
# 그래프 관련 코드
## color dictionary
color_dict = {0: 'red', 1: 'blue', 2:'red', 3:'blue'}
target_dict = {0: 'malignant_train', 1: 'benign_train', 2: 'malignant_test', 3:'benign_test'}
## 훈련한 classifier의 decision boundary를 그리는 함수
def plot_decision_boundary(X, clf, ax):
h = .02 # step size in the mesh
# create a mesh to plot in
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, h), np.arange(y_min, y_max, h))
Z = clf.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
ax.contour(xx, yy, Z, cmap='Blues')
# 캔버스 도식
fig = plt.figure()
ax = fig.add_subplot(1, 1, 1)
# malignant와 benign의 SVM decision boundary 그리기
plot_decision_boundary(pc, clf, ax)
#Train data 도식
for cluster in range(2):
sub_cancer_points = pc[train_y == cluster]
ax.scatter(sub_cancer_points[:, 0], sub_cancer_points[:, 1], edgecolor=color_dict[cluster], c='none', label=target_dict[cluster])
#Test data 도식
for cluster in range(2):
sub_cancer_points = pc_test[test_y == cluster]
ax.scatter(sub_cancer_points[:, 0], sub_cancer_points[:, 1], marker= 'x', c=color_dict[cluster+2], label=target_dict[cluster+2])
ax.set_xlabel('PC1')
ax.set_ylabel('PC2')
ax.set_title('PCA-Breast cancer dataset')
ax.legend()
ax.grid()
# Scoring
pca_test_accuracy_dict = Counter(clf.predict(pc_test) == test_y)
orig_test_accuracy_dict = Counter(clf_orig.predict(test_df) == test_y)
print("PCA 분석을 사용한 Test dataset accuracy: {}명/{}명 => {:.3f}".format(pca_test_accuracy_dict[True], sum(pca_test_accuracy_dict.values()), clf.score(pc_test, test_y)))
print("PCA를 적용하지 않은 Test dataset accuracy: {}명/{}명 => {:.3f}".format(orig_test_accuracy_dict[True], sum(orig_test_accuracy_dict.values()), clf_orig.score(test_df, test_y)))

T-SNE(T-Stochastic Neighbor Embedding)
- 시각화에 많이 쓰이는 알고리즘
- 고차원의 데이터를 1~3차원으로 불러들여와서 데이터를 시각적으로 이해
- 방사형적, 비선형적 데이터에서 PCA를 수행할 경우 많은 정보량을 담기 위한 주성분(Principal Component)으로 잡을 선형적인 축을 찾기 어렵다.
- T-SNE는 기존 차원의 공간에서 가까운 점들은, 차원축소된 공간에서도 여전히 가깝게 유지되는 것을 목표로 한다.
- 이러한 특징 덕분에 고차원의 데이터를 2차원으로 시각화해도, 예를 들어 MNIST의 784차원의 숫자 이미지를 2차원으로 시각화하여도, 같은 숫자의 이미지끼리 유사한 거리에 놓이게 된다.
- 즉 PCA는 데이터가 가진 고유한 물리적 정보량을 보존하는데 주력하지만, T-SNE는 고유한 물리적 정보량보다는 데이터들 간의 상대적 거리를 보존하는데 주력하다.
MNIST 숫자 데이터를 활용한 PCA 예제
# 불러운 데이터를 데이터프레임 형태로 변경
df = pd.DataFrame(mnist[0])
df['label'] = df['class'].apply(lambda i : str(i)[2])
n_image = mnist[0].shape[0]
pixel_columns = list(df.columns[:-2])
# 전체 데이터 중 1만개를 랜덤샘플링
import numpy as np
# 결과가 재생산 가능하도록 랜덤 시드를 지정
np.random.seed(30)
# 이미지 데이터의 순서를 랜덤으로 뒤바꾼(permutation) 배열을 담습니다.
rndperm = np.random.permutation(n_image)
# 랜덤으로 섞은 이미지 중 10,000개를 뽑고, df_subset에 담습니다.
n_image_sample = 10000
random_idx = rndperm[:n_image_sample]
df_subset = df.loc[random_idx,:].copy()
df_subset.shape
# PCA
from sklearn.decomposition import PCA
print(f"df_subset의 shape: {df_subset.shape}")
n_dimension = 2 # 축소시킬 목표 차원의 수
pca = PCA(n_components=n_dimension)
pca_result = pca.fit_transform(df_subset[pixel_columns].values) # 차원을 축소한 결과
df_subset['pca-one'] = pca_result[:,0] # 축소한 결과의 첫 번째 차원 값
df_subset['pca-two'] = pca_result[:,1] # 축소한 결과의 두 번째 차원 값
print(f"pca_result의 shape: {pca_result.shape}")
print(f"pca-1: {round(pca.explained_variance_ratio_[0],3)*100}%")
print(f"pca-2: {round(pca.explained_variance_ratio_[1],3)*100}%")
784차원의 데이터를 2차원으로 차원축소하면 전체의 16.9%의 정보량이 남는다.
plt.figure(figsize=(10,6))
sns.scatterplot(
x="pca-one", y="pca-two",
hue="label",
palette=sns.color_palette("hls", 10),
data=df_subset, # 2개의 PC축만 남은 데이터프레임 df_subset 을 시각화해 보자.
legend="full",
alpha=0.4
)
MNIST 숫자 데이터를 활용한 T-SNE예제
from sklearn.manifold import TSNE
print(f"df_subset의 shape: {df_subset.shape}")
data_subset = df_subset[pixel_columns].values
n_dimension = 2
tsne = TSNE(n_components=n_dimension)
tsne_results = tsne.fit_transform(data_subset)
print(f"tsne_results의 shape: {tsne_results.shape}")
# tsne 결과를 차원별로 추가
df_subset['tsne-2d-one'] = tsne_results[:,0]
df_subset['tsne-2d-two'] = tsne_results[:,1]
# 시각화
plt.figure(figsize=(10,6))
sns.scatterplot(
x="tsne-2d-one", y="tsne-2d-two",
hue="label",
palette=sns.color_palette("hls", 10),
data=df_subset,
legend="full",
alpha=0.3
)
T-SNE는 기존 차원의 공간에서 가까운 점들은, 차원축소된 공간에서도 여전히 가깝게 유지되는 것을 목표로 하고 있다. 이로 인해 MNIST의 숫자 데이터셋이 같은 숫자 이미지끼리 유사한 거리에 놓이는 것을 확인할 수 있다.
pca와 tsne의 차이점
PCA를 통해 차원축소를 진행할 경우, 두 점 사이의 거리가 PC축을 따라 발생한 거리가 아닐 경우 두 점 사이의 거리라는 중요 정보는 손실되고 실제로는 먼 거리의 점들이 가까운 점으로 투영될 수 있다.
반면 T-SNE에서는 기존 데이터의 점들 간 거리 데이터도 유지하고자 하므로 T-SNE를 시각화하면 숫자들 사이의 경계가 뚜렷이 나타나는 장점이 있다. 그래서 T-SNE 분류기의 feature extractor 모델은 카테고리 간 분류 경계선을 뚜렷히 유지하고 있는지를 확인하는 용도로 자주 쓰인다.
그러나 T-SNE를 통해 표현된 두 차원은 물리적 의미를 갖고 있지 않는다. PCA를 통해 추출된 PC선은 주성분이라는 물리적 의미를 유지하고 있으며 공분산을 통해 원본 데이터를 일부 복원할 수 있는 가능성을 갖고 있다. 그러나 TSNE는 정보 손실량에 주목하지 않아 저차원에 아무런 물리적 의미도 없고 오직 시각화에만 유리하다.
다음 표의 1~4에 들어갈 용어는?

'AI Theory > key concept of AI' 카테고리의 다른 글
| [NLP] Text Summarization (0) | 2023.07.17 |
|---|---|
| 사이킷런을 활용한 추천 시스템 (0) | 2023.07.07 |
| 선형 회귀와 로지스틱 회귀 (0) | 2023.07.05 |
| Regularization(정칙화) (0) | 2023.07.05 |
| 활성화 함수의 이해 (0) | 2023.07.03 |



